
💡 GRPO相比PPO主要优势: 1. 训练更稳定 引入 KL 散度惩罚项,有效控制策略更新的幅度,避免策略崩溃,提高训练的稳定性 GRPO用组内相对优势替代value model,消除了value估计误差 通过组内归一化,自动消除reward scale和bias的影响 实验中发现GRPO的advantage方差比PPO小30%左右,训练崩溃率更低 2. 工程更简单 只需要1-2个模型(policy + reference),而PPO需要4个 显存占用减少50%以上,训练速度提升2-3倍 超参数更少,更容易调优 3. 相对奖励机制 通过对同一输入生成的多个输出进行比较,GRPO 能够更稳定地估计优势函数,减少了训练过程中的方差 背景 GRPO是 DeepSeek-Math model中提出的对PPO方法的改进策略: 强化学习(RL)在提升模型数学推理能力方面被证明是有效的 传统PPO算法需要较大训练资源 GRPO作为PPO的变体被提出,可以更高效地优化模型 PPO Vs GRPO PPO回顾 PPO的目标函数为: \[\begin{aligned}J_{PPO}(\theta) =...
NLP
2026-03-26

这篇文章主要去“复盘”一下主流的长度外推结果,并试图从中发现免训练长度外推的关键之处。 问题定义 顾名思义,免训练长度外推,就是不需要用长序列数据进行额外的训练,只用短序列语料对模型进行训练,就可以得到一个能够处理和预测长序列的模型,即“Train Short, Test Long”。那么如何判断一个模型能否用于长序列呢?最基本的指标就是模型的长序列Loss或者PPL不会爆炸,更加符合实践的评测则是输入足够长的Context,让模型去预测答案,然后跟真实答案做对比,算BLEU、ROUGE等, LongBench 就是就属于这类榜单。 但要注意的是,长度外推应当不以牺牲远程依赖为代价——否则考虑长度外推就没有意义了,倒不如直接截断文本——这意味着通过显式地截断远程依赖的方案都需要谨慎选择,比如ALIBI,还有带显式Decay的 线性RNN ,这些方案当序列长度足够大时都表现为局部注意力,即便有可能实现长度外推,也会有远程依赖不足的风险,需要根据自己的场景斟酌使用。 如何判断在长度外推的同时有没有损失远程依赖呢?比较严谨的是像 ReRoPE...
Large Model
2026-03-18
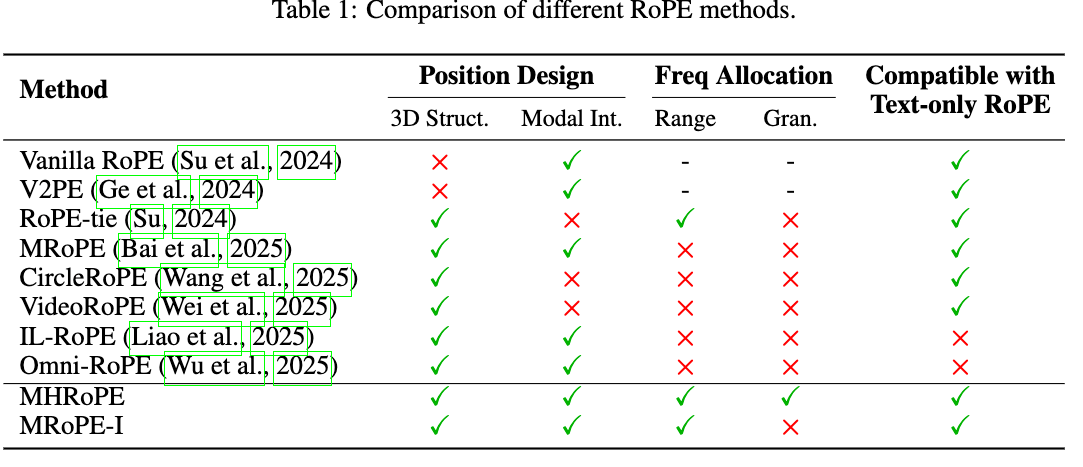
简介 论文: 《REVISITING MULTIMODAL POSITIONAL ENCODING IN VISION–LANGUAGE MODELS》 通过对多模态旋转位置嵌入(RoPE)的两个核心组件——位置设计和频率分配进行综合分析。通过实验,确定了三个关键指南:位置一致性、频率全利用和保留文本先验。基于这些见解,提出了多头RoPE(MHRoPE)和MRoPE-Interleave(MRoPE-I),这两种简单且即插即用的变体不需要任何架构更改。 为了构建更稳健的多模态位置编码,作者在MRoPE的基础上,系统地探索了三个未充分研究的方案: 位置设计——如何为文本和视觉标记分配无歧义、分离良好的坐标; 频率分配——如何将旋转频率分配到每个位置轴的嵌入维度; 与纯文本RoPE的兼容性——确保设计默认为标准RoPE,以便进行有效的迁移学习。 Vanilla RoPE RoPE与加性位置嵌入不同,RoPE对query和key向量应用旋转变换,从而将相对位置依赖直接纳入自注意力机制。给定位置 \(m\) 的查询向量 \(q\) 和位置 \(n\) 的键向量 \(k\) ,注意力分数...
NLP
2026-03-16
不同于RNN、CNN等模型,对于Transformer模型来说,位置编码的加入是必不可少的,因为纯粹的Attention模块是无法捕捉输入顺序的,即无法区分不同位置的Token。为此我们大体有两个选择: 想办法将位置信息融入到输入中,这构成了绝对位置编码的一般做法; 想办法微调一下Attention结构,使得它有能力分辨不同位置的Token,这构成了相对位置编码的一般做法。 虽然说起来主要就是绝对位置编码和相对位置编码两大类,但每一类其实又能衍生出各种各样的变种,为此研究人员可算是煞费苦心、绞尽脑汁了,此外还有一些不按套路出牌的位置编码。本文就让我们来欣赏一下研究人员为了更好地表达位置信息所构建出来的“八仙过海,各显神通”般的编码方案。 绝对位置编码 形式上来看,绝对位置编码是相对简单的一种方案,但即便如此,也不妨碍各路研究人员的奇思妙想,也有不少的变种。一般来说,绝对位置编码会加到输入中:在输入的第 𝑘 个向量 \(𝑥_𝑘\) 中加入位置向量 \(𝑝_𝑘\) 变为 \(\boldsymbol{x}_k + \boldsymbol{p}_k\) ,其中 \(...
Large Model
2026-03-10

问题背景 首先简化一下问题,本文所讨论的多模态,主要指图文混合的双模态,即输入和输出都可以是图文。可能有不少读者的第一感觉是:多模态模型难道不也是烧钱堆显卡,Transformer“一把梭”,最终“大力出奇迹”吗? 其实没那么简单。先看文本生成,事实上文本生成自始至终都只有一条主流路线,那就是语言模型,即建模条件概率 \(p(x_t|x_1,\cdots,x_{t-1})\) ,不论是最初的 n-gram语言模型,还是后来的Seq2Seq、GPT,都是这个条件概率的近似。也就是说,一直以来,人们对“实现文本生成需要往哪个方向走”是很明确的,只是背后所用的模型有所不同,比如LSTM、CNN、Attention乃至最近复兴的线性RNN等。所以, 文本生成确实可以All in Transformer来大力出奇迹,因为方向是标准的、清晰的。 然而,对于图像生成,并没有这样的“标准方向”。就本站所讨论过的图像生成模型,就有 VAE 、 GAN 、 Flow 、 Diffusion ,还有小众的 EBM...
Large Model
2026-03-10

k1.5—CoT强化训练 概述 Kimi k1.5采用了一种简化而有效的强化学习框架,其核心在于长上下文扩展和改进的策略优化方法,而不依赖于更复杂的技术如蒙特卡洛树搜索、价值函数和过程奖励模型。 问题设定 给定训练数据集 \(D = \{(x_i, y^*_i)\}_{i=1}^n\) ,其中包含问题 \(x_i\) 和对应的真实答案 \(y^*_i\) ,目标是训练一个策略模型 \(\pi_\theta\) 来准确解决测试问题。在复杂推理场景中,思维链(CoT)方法提出使用一系列中间步骤 \(z = (z_1, z_2, ..., z_m)\) 来连接问题 \(x\) 和答案 \(y\) ,每个 \(z_i\) 是解决问题的重要中间步骤。 当解决问题 \(x\) 时,思维 \(z_t \sim \pi_\theta(\cdot|x, z_1, ..., z_{t-1})\) 被自回归采样,最终答案 \(y \sim \pi_\theta(\cdot|x, z_1, ..., z_m)\) 。 强化学习目标 基于真实答案 \(y^*\) ,分配一个值 \(r(x, y, y^*)...
Generative Model
2026-03-04

SD模型原理 SD是CompVis、Stability AI和LAION等公司研发的一个文生图模型,它的模型和代码是开源的,而且训练数据LAION-5B也是开源的。SD在开源90天github仓库就收获了 33K的stars ,可见这个模型是多受欢迎。 SD是一个 基于latent的扩散模型 ,它在UNet中引入text condition来实现基于文本生成图像。SD的核心来源于 Latent Diffusion 这个工作,常规的扩散模型是基于pixel的生成模型,而Latent Diffusion是基于latent的生成模型,它先采用一个autoencoder将图像压缩到latent空间,然后用扩散模型来生成图像的latents,最后送入autoencoder的decoder模块就可以得到生成的图像。 基于latent的扩散模型的优势在于计算效率更高效,因为图像的latent空间要比图像pixel空间要小,这也是SD的核心优势...
Generative Model
2026-03-04
技术分析 从方法上来看,条件控制生成的方式分两种: 事后修改(Classifier-Guidance)和事前训练(Classifier-Free) 。 对于大多数人来说,一个SOTA级别的扩散模型训练成本太大了,而分类器(Classifier)的训练还能接受,所以就想着直接复用别人训练好的无条件扩散模型,用一个分类器来调整生成过程以实现控制生成,这就是事后修改的Classifier-Guidance方案;而对于“财大气粗”的Google、OpenAI等公司来说,它们不缺数据和算力,所以更倾向于往扩散模型的训练过程中就加入条件信号,达到更好的生成效果,这就是事前训练的Classifier-Free方案。 Classifier-Guidance方案最早出自 《Diffusion Models Beat GANs on Image Synthesis》 ,最初就是用来实现按类生成的;后来 《More Control for Free! Image Synthesis with Semantic Diffusion Guidance》...
Generative Model
2026-03-04

Flow Matching 其实是将 flow 的离散形式转换为连续形式(连续标准化流CNF),进而可以看成是一个ODE方程,实际求解的是这个ODE 求解的核心思路是:构建速度场通过数值积分求解位移,也就是通过预测速度场,从而转为ode求解 从概率路径的角度上来说,解是无穷多的,不同的方法本质上讲是在于构造尽可能简单、直接、易解的概率路径 通过不同的条件概率路径,可以构造出VP(score matching)、 VE(diffusion)、OT(1-rectified flow)等形式 实际的边缘概率分布路径并不是一条直线 ,我们是通过拟合条件速度场来逼近边缘速度场, 即使我们证明了对于参数 \(\theta\) 来说优化目标是等价的,但终究还是有一些gap Flow-based Models Normalizing Flow Normalizing Flow 是一种基于 变换 对概率分布进行建模的模型,其通过一系列 离散且可逆的变换 实现任意分布与先验分布(例如标准高斯分布)之间的相互转换。在 Normalizing Flow...
Generative Model
2026-03-04

Diffusion Models from SDE 连续扩散模型 (Continuous Diffusion Models) 将传统的离散时间扩散过程扩展到连续时间域,可以被视为一个随机过程,使用随机微分方程(SDE)来描述。其前向过程可以写成如下形式: \[\mathrm d\mathbf x=\mathbf f(\mathbf x,t)\mathrm dt+g(t)\mathrm d\mathbf w\tag{1}\] 其中, \(f(x,t)\) 可以看成偏移系数, \(g(t)\) 可以看成是扩散系数, \(dw\) 是标准布朗运动。这个SDE 描述了数据在连续时间域内如何被噪声逐渐破坏。 这个随机过程的 逆向过程 存在(更准确的描述:下面的逆向时间SDE具有 与正向过程SDE相同的联合分布 )为 \[d\mathbf{x}=[\mathbf{f}(\mathbf{x},t)-g^2(t)\nabla_{\mathbf{x}}\log p_t(\mathbf{x})]dt+g(t)d\bar{\mathbf{w}}\tag{2}\]...
Generative Model
2026-03-04

DDPM 有一个非常明显的问题:采样过程很慢。因为 DDPM 的反向过程利用了马尔可夫假设, 所以每次都必须在相邻的时间步之间进行去噪,而不能跳过中间步骤 。原始论文使用了 1000 个时间步,所以我们在采样时也需要循环 1000 次去噪过程,这个过程是非常慢的。 为了加速 DDPM 的采样过程,DDIM 在不利用马尔可夫假设的情况下推导出了 diffusion 的反向过程,最终可以实现仅采样 20~100 步的情况下达到和 DDPM 采样 1000 步相近的生成效果,也就是提速 10~50 倍。这篇文章将对 DDIM 的理论进行讲解,并实现 DDIM 采样的代码。 DDPM 的反向过程 首先我们回顾一下 DDPM 反向过程的推导,为了推导出 \(q(\mathbf{x}_{t-1}|\mathbf{x}_t)\) 这个条件概率分布,DDPM 利用贝叶斯公式将其变成了先验分布的组合, 并且通过向条件中加入 \(\mathbf{x}_0 \) 将所有的分布转换为已知分布 :...
Generative Model
2026-03-03

1-Rectified Flow 可以认为是 flow matching的ot最优传输形式 Rectified Flow目的是将多对多无约束映射 转变成 一对一有约束映射。 ode会保证路径是“因果”的,也就是避免相交的情况 2-Rectified Flow或者叫Reflow 核心的实际上是加噪过程的样本交点数目降低,交点处模型无法精确学习向量场,交点数少了,模型在每个点预测都更准了,加噪过程是直线,所以能更少步数走到起点(但整体采样过程不是直线) 原本随机采样的DDPM模型中,也隐含了一个确定性的采样过程DDIM,它的连续极限也是一个ODE 。 细想上述过程, 可以发现不管是“DDPM→DDIM”还是“SDE→ODE”,都是从随机采样模型过渡到确定性模型,而如果我们一开始的目标就是ODE,那么该过程未免显得有点“迂回”了 。在本文中,笔者尝试给出ODE扩散模型的直接推导,并揭示了它与雅可比行列式、热传导方程等内容的联系。 Rectified Flow 理论推导 微分方程...