
💡 GRPO相比PPO主要优势: 1. 训练更稳定 引入 KL 散度惩罚项,有效控制策略更新的幅度,避免策略崩溃,提高训练的稳定性 GRPO用组内相对优势替代value model,消除了value估计误差 通过组内归一化,自动消除reward scale和bias的影响 实验中发现GRPO的advantage方差比PPO小30%左右,训练崩溃率更低 2. 工程更简单 只需要1-2个模型(policy + reference),而PPO需要4个 显存占用减少50%以上,训练速度提升2-3倍 超参数更少,更容易调优 3. 相对奖励机制 通过对同一输入生成的多个输出进行比较,GRPO 能够更稳定地估计优势函数,减少了训练过程中的方差 背景 GRPO是 DeepSeek-Math model中提出的对PPO方法的改进策略: 强化学习(RL)在提升模型数学推理能力方面被证明是有效的 传统PPO算法需要较大训练资源 GRPO作为PPO的变体被提出,可以更高效地优化模型 PPO Vs GRPO PPO回顾 PPO的目标函数为: \[\begin{aligned}J_{PPO}(\theta) =...
杂七杂八
2026-03-27
生成器 什么是生成器? 通过列表生成式,我们可以直接创建一个列表,但是,受到内存限制,列表容量肯定是有限的,而且创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。 所以,如果列表元素可以按照某种算法推算出来,那我们是否可以在循环的过程中不断推算出后续的元素呢?这样就不必创建完整的list,从而节省大量的空间,在Python中, 这种一边循环一边计算的机制,称为生成器:generator 生成器是一个特殊的程序,可以被用作控制循环的迭代行为,python中生成器是迭代器的一种,使用 yield 返回值函数,每次调用 yield 会暂停,而可以使用 next() 函数和 send() 函数恢复生成器。 生成器类似于返回值为数组的一个函数,这个函数可以接受参数,可以被调用,但是,不同于一般的函数会一次性返回包括了所有数值的数组,生成器一次只能产生一个值,这样消耗的内存数量将大大减小,而且允许调用函数可以很快的处理前几个返回值,因此生成器看起来像是一个函数,但是表现得却像是迭代器 python中的生成器...
杂七杂八
2026-03-27
概述 python采用的是 引用计数 机制为主, 标记-清除 和 分代收集 两种机制为辅的策略。 引用计数 Python语言默认采用的垃圾收集机制是『引用计数法 Reference Counting 』,该算法最早George E. Collins在1960的时候首次提出,50年后的今天,该算法依然被很多编程语言使用。 『引用计数法』的原理是:每个对象维护一个 ob_ref 字段,用来记录该对象当前被引用的次数,每当新的引用指向该对象时,它的引用计数 ob_ref 加 1 ,每当该对象的引用失效时计数 ob_ref 减 1 ,一旦对象的引用计数为 0 ,该对象立即被回收,对象占用的内存空间将被释放。 它的缺点是需要额外的空间维护引用计数,这个问题是其次的,不过最主要的问题是它不能解决对象的“循环引用”,因此,也有很多语言比如Java并没有采用该算法做来垃圾的收集机制。 引用计数案例 import sys
class A():
def __init__(self):
'''初始化对象'''
print('object born id:%s'...
杂七杂八
2026-03-27

列表和元组总结 列表和元组都是 一个可以放置任意数据类型的有序集合 ,他们有以下共同点 列表和元组中的元素可以任意,并且都可以嵌套。 列表和元组都支持索引,且都支持负数索引,-1表示最后一个元素,-2表示倒数第二个元素 列表和元组都支持切片操作 都支持in关键词 都可以使用 .index() 、 .count() 、 sorted() 和 enumerate() 等方法 两者之间的相互转换,list()和tuple() 但是他们也是有区别 列表是动态的,长度大小不固定,可以随意地增加、删减或者改变元素(mutable) 元组是静态的,长度大小不固定,无法增删改,想要对已有的元组做任何“改变”,就只能开辟一块内存,创建新的元组 列表和元组存储方式的差异 由于列表是动态的;元组是静态的,不可变的。这样的差异,势必会影响两者存储方式。我们可以来看下面的例子: >>> l = [1, 2, 3]
>>> l.__sizeof__()
64
>>> tup = (1, 2, 3)
>>> tup.__sizeof__()
48...
Large Model
2026-03-10

k1.5—CoT强化训练 概述 Kimi k1.5采用了一种简化而有效的强化学习框架,其核心在于长上下文扩展和改进的策略优化方法,而不依赖于更复杂的技术如蒙特卡洛树搜索、价值函数和过程奖励模型。 问题设定 给定训练数据集 \(D = \{(x_i, y^*_i)\}_{i=1}^n\) ,其中包含问题 \(x_i\) 和对应的真实答案 \(y^*_i\) ,目标是训练一个策略模型 \(\pi_\theta\) 来准确解决测试问题。在复杂推理场景中,思维链(CoT)方法提出使用一系列中间步骤 \(z = (z_1, z_2, ..., z_m)\) 来连接问题 \(x\) 和答案 \(y\) ,每个 \(z_i\) 是解决问题的重要中间步骤。 当解决问题 \(x\) 时,思维 \(z_t \sim \pi_\theta(\cdot|x, z_1, ..., z_{t-1})\) 被自回归采样,最终答案 \(y \sim \pi_\theta(\cdot|x, z_1, ..., z_m)\) 。 强化学习目标 基于真实答案 \(y^*\) ,分配一个值 \(r(x, y, y^*)...

48. 旋转图像 题目 给定一个 \(n × n\) 的二维矩阵 matrix 表示一个图像。请你将图像顺时针旋转 90 度。 你必须在 原地 旋转图像,这意味着你需要直接修改输入的二维矩阵。 请不要 使用另一个矩阵来旋转图像。 示例 1: 输入:matrix = [[1,2,3],[4,5,6],[7,8,9]]
输出:[[7,4,1],[8,5,2],[9,6,3]] 示例 2: 输入:matrix = [[5,1,9,11],[2,4,8,10],[13,3,6,7],[15,14,12,16]]
输出:[[15,13,2,5],[14,3,4,1],[12,6,8,9],[16,7,10,11]] 提示: n == matrix.length == matrix[i].length 1 <= n <= 20 -1000 <= matrix[i][j] <= 1000 题解 这是一个经典的矩阵操作问题。要在原地(In-place)将图像顺时针旋转 90 度,我们可以利用矩阵的几何性质。 最直观且易于实现的方法是将...
线性结构与技巧 基础容器 数组 (Array) 链表 (Linked List) 字符串 (String) KMP算法 核心技巧 双指针 滑动窗口 二分查找 栈与队列 栈 & 队列 (Stack & Queue) 单调队列 树与图论 树与堆 (Tree & Heap) 树的遍历 二叉树 堆(大顶堆&小顶堆) 优先队列 图 (Graph) 搜索(BFS/DFS) 最小生成树 核心算法思想 动态规划 (DP) 基础 DP 背包问题 排序 基础排序算法 排序算法 数据处理 哈希表 Math
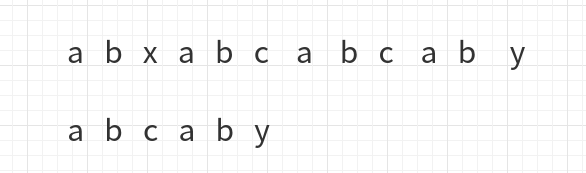
kmp算法用于字符串的模式匹配,也就是找到模式字符串在目标字符串的第一次出现的位置比如 abababc 那么 bab 在其位置1处, bc 在其位置5处,我们首先想到的最简单的办法就是蛮力的一个字符一个字符的匹配,但那样的时间复杂度会是 \(O(m*n)\) 。kmp算法保证了时间复杂度为 \(O(m+n)\) 。 基本原理 举个例子: 发现 x 与 c 不同后,进行移动 a 与 x 不同,再次移动 此时比较到了 c 与 y , 于是下一步移动成了下面这样 这一次的移动与前两次的移动不同,之前每次比较到上面长字符串的字符位置后,直接把模式字符串的首字符与它对齐,这次并没有,原因是这次移动之前, y 与 c 对齐,但是 y 前边的 ab 是与自己的前缀 ab 一样,于是 ab 并不用再比较,直接从第三个位置开始比较,如图: 所以说 kmp算法对于这种情况就直接使用当前比较字符之前的最长相同的前后缀,然后将前缀与上面的长字符串对齐,继续比较后面的字符串 。 这里kmp算法中的一个重要点就来了,如何找到 模式字符串中每位字符之前的最长相同前后缀呢 这里继续用一个例子举例: 下面的数字记录...
💡 不断排除不存在解的区间,直至最后剩下一个 这里归纳最重要的部分: 分析题意,挖掘题目中隐含的 单调性; while (left < right) 退出循环的时候有 left == right 成立,因此无需考虑返回 left 还是 right ; 始终思考下一轮搜索区间是什么,如果是 [mid, right] 就对应 left = mid ,如果是 [left, mid - 1] 就对应 right = mid - 1 ,是保留 mid 还是 +1、−1 就在这样的思考中完成; 从一个元素什么时候不是解开始考虑下一轮搜索区间是什么 ,把区间分为 2个部分(一个部分肯定不存在目标元素,另一个部分有可能存在目标元素),问题会变得简单很多,这是一条 非常有用 的经验; 每一轮区间被划分成 2 部分,理解 区间划分 决定中间数取法( 无需记忆,需要练习 + 理解 ),在调试的过程中理解 区间和中间数划分的配对关系: 划分 [left, mid] 与 [mid + 1, right] ,mid 被分到左边,对应 int mid = left + (right - left) / 2 ;...
164. 最大间距 题目 给定一个无序的数组,找出数组在排序之后,相邻元素之间最大的差值。 如果数组元素个数小于 2,则返回 0。 Example 1: Input: [3,6,9,1]
Output: 3
Explanation: The sorted form of the array is [1,3,6,9], either
(3,6) or (6,9) has the maximum difference 3. 题解 如果进行排序,这里会超时。采用桶排序 基础排序算法 的思想,可以在线性时间解决。 首先建立桶,每个桶中只需要存放这个桶中元素的最大值和最小值。 我们期望将数组中的各个数等距离分配,也就是每个桶的长度相同,也就是对于所有桶来说,桶内最大值减去桶内最小值都是一样的。可以当成公式来记。 \[每个桶的长度=\max(1,\lfloor{{\max(nums)-\min(nums)}\over{len(nums)-1}}\rfloor)\tag{1}\]...
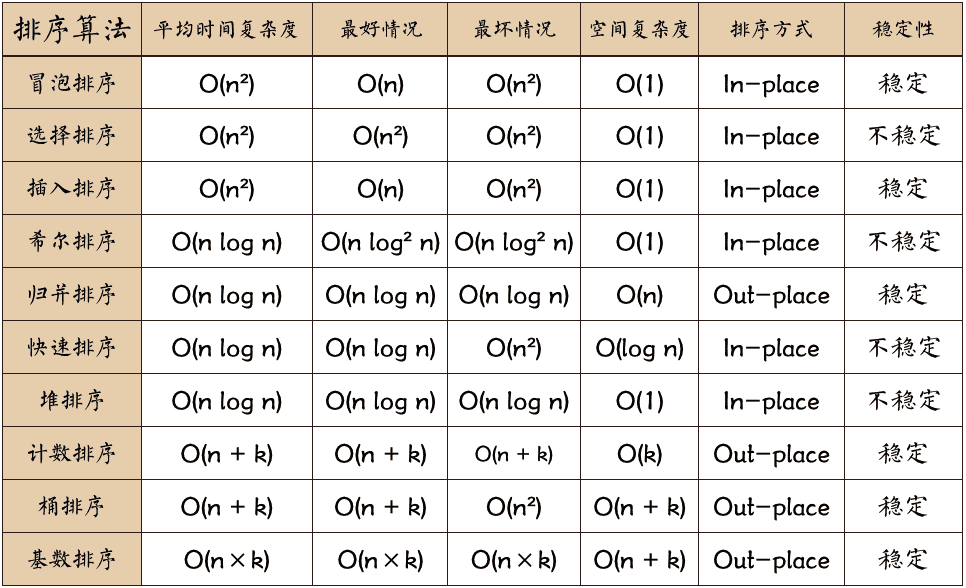
排序算法是《数据结构与算法》中最基本的算法之一。 排序算法可以分为内部排序和外部排序,内部排序是数据记录在内存中进行排序,而外部排序是因排序的数据很大,一次不能容纳全部的排序记录,在排序过程中需要访问外存。常见的内部排序算法有:插入排序、希尔排序、选择排序、冒泡排序、归并排序、快速排序、堆排序、基数排序等。用一张图概括: 冒泡排序 冒泡排序(Bubble Sort)是一种简单的排序算法,它通过重复地遍历待排序的列表,比较相邻的元素并交换它们的位置来实现排序。该算法的名称来源于较小的元素会像"气泡"一样逐渐"浮"到列表的顶端。 算法步骤 比较相邻元素 :从列表的第一个元素开始,比较相邻的两个元素。 交换位置 :如果前一个元素比后一个元素大,则交换它们的位置。 重复遍历 :对列表中的每一对相邻元素重复上述步骤,直到列表的末尾。这样,最大的元素会被"冒泡"到列表的最后。 缩小范围 :忽略已经排序好的最后一个元素,重复上述步骤,直到整个列表排序完成。 假设有一个待排序的列表 [5, 3, 8, 4, 6] ,冒泡排序的过程如下: 第一轮遍历 : 比较 5 和 3,交换位置,列表变为 [3,...
Algorithm
2026-02-25
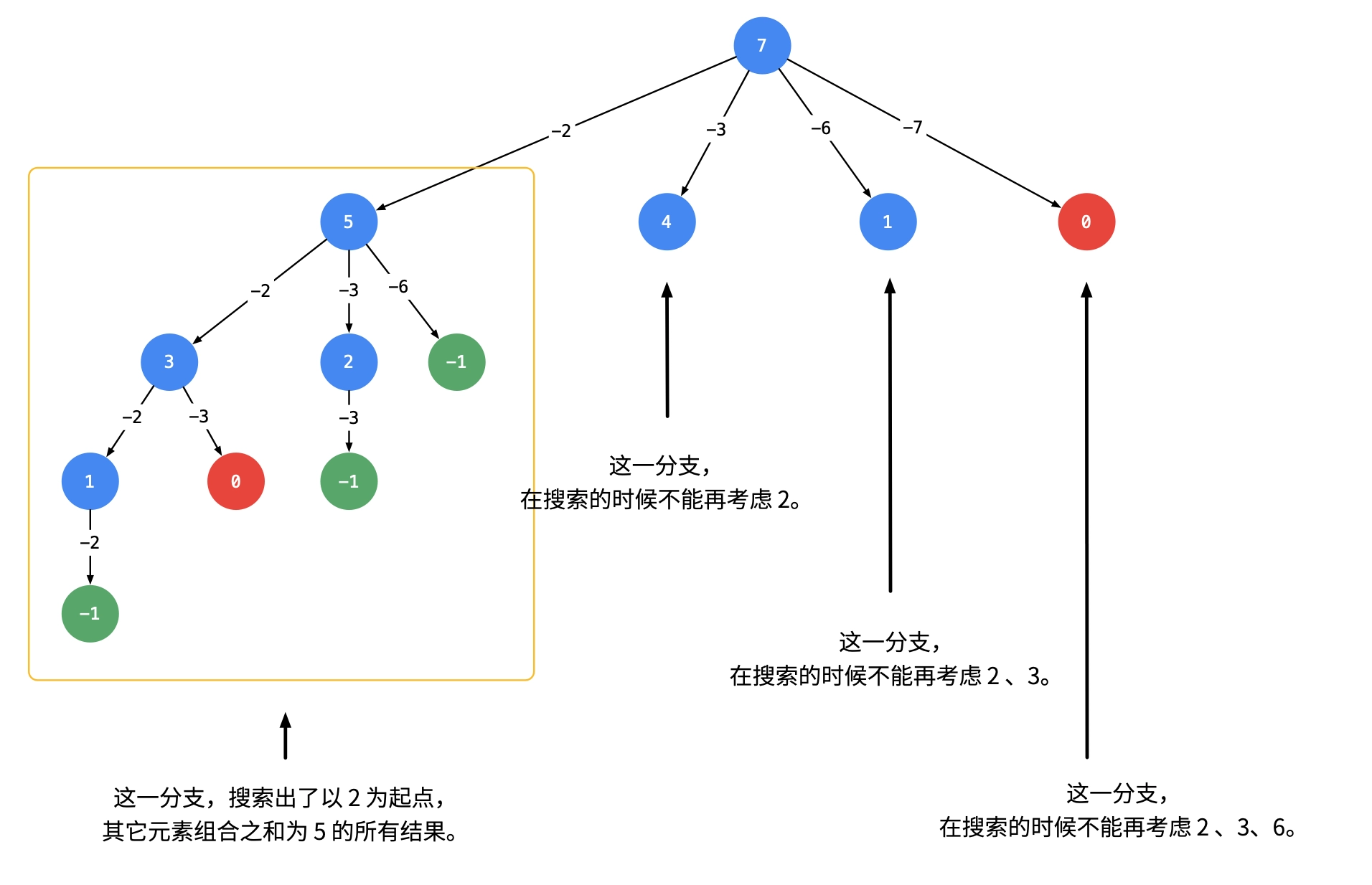
DFS 39&40. 组合总和 题目 给你一个 无重复元素 的整数数组 candidates 和一个目标整数 target ,找出 candidates 中可以使数字和为目标数 target 的 所有 不同组合 ,并以列表形式返回。你可以按 任意顺序 返回这些组合。 candidates 中的 同一个 数字可以 无限制重复被选取 。如果至少一个数字的被选数量不同,则两种组合是不同的。 对于给定的输入,保证和为 target 的不同组合数少于 150 个。 示例 1: 输入:candidates = [2,3,6,7], target = 7
输出:[[2,2,3],[7]]
解释:
2 和 3 可以形成一组候选,2 + 2 + 3 = 7 。注意 2 可以使用多次。
7 也是一个候选, 7 = 7 。
仅有这两种组合。 示例 2: 输入: candidates = [2,3,5], target = 8
输出: [[2,2,2,2],[2,3,3],[3,5]] 示例 3: 输入: candidates = [2], target = 1
输出: [] 提示: 1 <=...