
💡 GRPO相比PPO主要优势: 1. 训练更稳定 引入 KL 散度惩罚项,有效控制策略更新的幅度,避免策略崩溃,提高训练的稳定性 GRPO用组内相对优势替代value model,消除了value估计误差 通过组内归一化,自动消除reward scale和bias的影响 实验中发现GRPO的advantage方差比PPO小30%左右,训练崩溃率更低 2. 工程更简单 只需要1-2个模型(policy + reference),而PPO需要4个 显存占用减少50%以上,训练速度提升2-3倍 超参数更少,更容易调优 3. 相对奖励机制 通过对同一输入生成的多个输出进行比较,GRPO 能够更稳定地估计优势函数,减少了训练过程中的方差 背景 GRPO是 DeepSeek-Math model中提出的对PPO方法的改进策略: 强化学习(RL)在提升模型数学推理能力方面被证明是有效的 传统PPO算法需要较大训练资源 GRPO作为PPO的变体被提出,可以更高效地优化模型 PPO Vs GRPO PPO回顾 PPO的目标函数为: \[\begin{aligned}J_{PPO}(\theta) =...
Large Model
2026-03-18
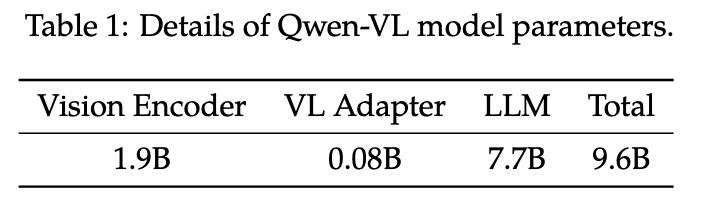
Qwen-VL 模型框架 Qwen-VL的整体网络架构由三个组件组成: LLM:使用 Qwen-7B 的预训练权重进行初始化。 视觉编码器:Qwen-VL 的可视化编码器使用ViT 架构,使用 Openclip 的 ViT-bigG 的预训练权重进行初始化。在训练和推理过程中,输入图像的大小都会调整为特定分辨率。视觉编码器通过以 14 步幅将图像分割成块来处理图像,生成一组图像特征。 位置感知视觉语言适配器:为了缓解长图像特征序列带来的效率问题,Qwen-VL 引入了一种视觉语言适配器来压缩图像特征。类似QFormer,该适配器包括一个随机初始化的单层交叉注意力模块。使用一组可训练向量(嵌入)作为query,并将视觉编码器中的图像特征作为交叉注意力作的key。该机制将视觉特征序列压缩到固定长度 256。 图像输入 图像不会直接以像素形式喂给语言模型(LLM)。 典型流程是: Visual Encoder :把图片编码成一串视觉特征(embedding/feature sequence)。 Adapter :把视觉特征映射到语言模型可接入的表征空间/维度。 最终得到:...
Large Model
2026-03-18
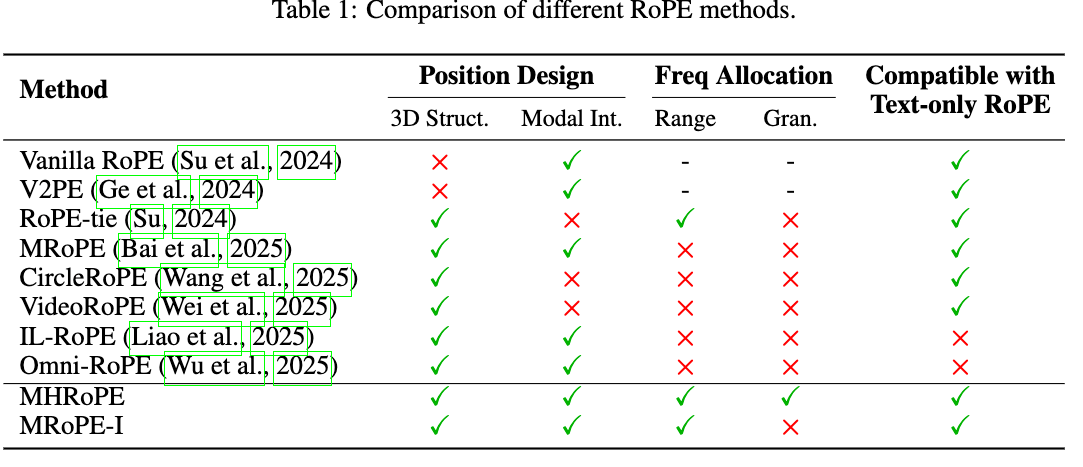
简介 论文: 《REVISITING MULTIMODAL POSITIONAL ENCODING IN VISION–LANGUAGE MODELS》 通过对多模态旋转位置嵌入(RoPE)的两个核心组件——位置设计和频率分配进行综合分析。通过实验,确定了三个关键指南:位置一致性、频率全利用和保留文本先验。基于这些见解,提出了多头RoPE(MHRoPE)和MRoPE-Interleave(MRoPE-I),这两种简单且即插即用的变体不需要任何架构更改。 为了构建更稳健的多模态位置编码,作者在MRoPE的基础上,系统地探索了三个未充分研究的方案: 位置设计——如何为文本和视觉标记分配无歧义、分离良好的坐标; 频率分配——如何将旋转频率分配到每个位置轴的嵌入维度; 与纯文本RoPE的兼容性——确保设计默认为标准RoPE,以便进行有效的迁移学习。 Vanilla RoPE RoPE与加性位置嵌入不同,RoPE对query和key向量应用旋转变换,从而将相对位置依赖直接纳入自注意力机制。给定位置 \(m\) 的查询向量 \(q\) 和位置 \(n\) 的键向量 \(k\) ,注意力分数...
Large Model
2026-03-10

问题背景 首先简化一下问题,本文所讨论的多模态,主要指图文混合的双模态,即输入和输出都可以是图文。可能有不少读者的第一感觉是:多模态模型难道不也是烧钱堆显卡,Transformer“一把梭”,最终“大力出奇迹”吗? 其实没那么简单。先看文本生成,事实上文本生成自始至终都只有一条主流路线,那就是语言模型,即建模条件概率 \(p(x_t|x_1,\cdots,x_{t-1})\) ,不论是最初的 n-gram语言模型,还是后来的Seq2Seq、GPT,都是这个条件概率的近似。也就是说,一直以来,人们对“实现文本生成需要往哪个方向走”是很明确的,只是背后所用的模型有所不同,比如LSTM、CNN、Attention乃至最近复兴的线性RNN等。所以, 文本生成确实可以All in Transformer来大力出奇迹,因为方向是标准的、清晰的。 然而,对于图像生成,并没有这样的“标准方向”。就本站所讨论过的图像生成模型,就有 VAE 、 GAN 、 Flow 、 Diffusion ,还有小众的 EBM...
Large Model
2026-03-10

k1.5—CoT强化训练 概述 Kimi k1.5采用了一种简化而有效的强化学习框架,其核心在于长上下文扩展和改进的策略优化方法,而不依赖于更复杂的技术如蒙特卡洛树搜索、价值函数和过程奖励模型。 问题设定 给定训练数据集 \(D = \{(x_i, y^*_i)\}_{i=1}^n\) ,其中包含问题 \(x_i\) 和对应的真实答案 \(y^*_i\) ,目标是训练一个策略模型 \(\pi_\theta\) 来准确解决测试问题。在复杂推理场景中,思维链(CoT)方法提出使用一系列中间步骤 \(z = (z_1, z_2, ..., z_m)\) 来连接问题 \(x\) 和答案 \(y\) ,每个 \(z_i\) 是解决问题的重要中间步骤。 当解决问题 \(x\) 时,思维 \(z_t \sim \pi_\theta(\cdot|x, z_1, ..., z_{t-1})\) 被自回归采样,最终答案 \(y \sim \pi_\theta(\cdot|x, z_1, ..., z_m)\) 。 强化学习目标 基于真实答案 \(y^*\) ,分配一个值 \(r(x, y, y^*)...
Large Model
2026-03-06
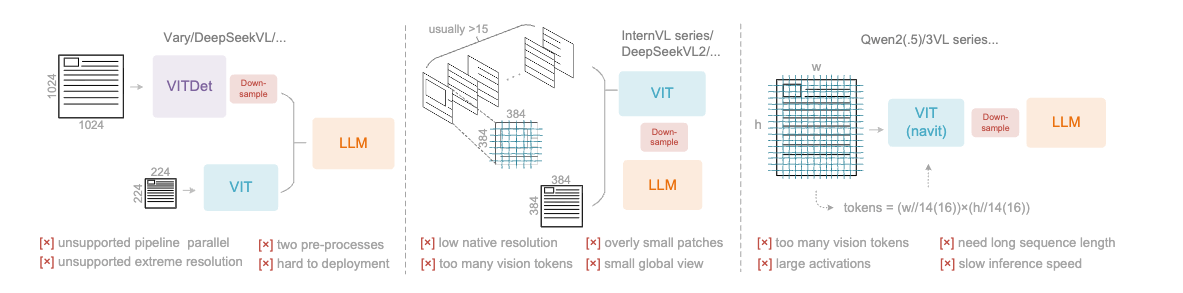
DeeSeek-OCR 简介 当前的大型语言模型(LLMs)在处理长文本时面临显著的计算挑战,其开销随序列长度呈二次增长。本文探索一种潜在的解决方案:将视觉模态作为高效的文本信息压缩媒介。 单张包含文档文本的图像,能够用显著更少的 token 表达丰富信息,相比等量的数字文本更为紧凑;这表明,通过视觉 token 进行光学压缩有望实现更高的压缩比。 本文关注视觉编码器如何提升 LLM 在处理文本信息时的效率,而非人类本就擅长的基础 VQA 任务 当前主流 VLM 视觉编码器的问题 第一类是以 Vary 为代表的双塔(dual-tower)架构,通过并行的 SAM 编码器来提升高分辨率图像处理时的视觉词表参数规模。该方法虽然在参数量与激活内存上更可控,但也存在显著缺点:需要对图像进行两套预处理,增加了部署复杂度;同时在训练中使编码器管线的并行化变得困难。 第二类是以 InternVL2.0 为代表的切片(tile-based)方法,通过将图像划分为小块并行处理,在高分辨率场景下降低激活内存。尽管这种方法能够处理极高分辨率,但由于其原生编码器分辨率通常较低(低于...
Large Model
2026-03-04
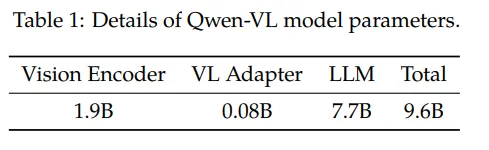
Qwen-VL系列 Qwen-VL 阿里巴巴的Qwen-VL是另一个比较经典的模型,十分值得作为案例介绍多模态大模型的训练要点。Qwen-VL使用Qwen-7B LLM作为语言模型基座,Openclip预训练的ViT-bigG作为视觉特征Encoder,随机初始化的单层Cross-Attention模块作为视觉和自然语言的的Adapter,总参数大小约9.6B。 如下图,Qwen-VL的训练过程分为三个阶段: Stage1 为预训练,目标是使用大量的图文Pair对数据对齐视觉模块和LLM的特征,这个阶段冻结LLM模块的参数; Stage2 为多任务预训练,使用更高质量的图文多任务数据(主要来源自开源VL任务,部分自建数据集),更高的图片像素输入,全参数训练; Stage3 为指令微调阶段,这个阶段冻结视觉Encoder模块,使用的数据主要来自大模型Self-Instruction方式自动生成,目标是提升模型的指令遵循和多轮对话能力。...
Large Model
2026-03-04

项目: https://llava-vl.github.io/ github: https://github.com/haotian-liu/LLaVA 一句话 优点 : 极大简化了VLM的训练方式:Pre-training + Instruction Tuning 训练量得到简化:1M量级数据+ 8卡A100 → 一天完成训练 LLaVA LLaVA是2023的连续工作,包含了LLaVA 1.0, 1.5, 1.6几个版本(后续会有更多),也是2023年多模态领域妥妥的顶流。发表9个月620的stars,GitHub超过12K的stars。 LLaVA它的网络结构简单、微调成本比较低,任何研究组、企业甚至个人都可以基于它构建自己的领域的多模态模型。 非常建议对多模态大模型感兴趣的朋友关注LLaVA这篇工作。 简介...
Deep Learning
2026-03-02

Random erasing data augmentation 论文名称:Random erasing data augmentation 论文地址: https://arxiv.org/pdf/1708.04896v2.pdf 随机擦除增强,非常容易理解。作者提出的目的主要是模拟遮挡,从而提高模型泛化能力,这种操作其实非常make sense,因为我把物体遮挡一部分后依然能够分类正确,那么肯定会迫使网络利用局部未遮挡的数据进行识别,加大了训练难度,一定程度会提高泛化能力。其也可以被视为add noise的一种,并且与随机裁剪、随机水平翻转具有一定的互补性,综合应用他们,可以取得更好的模型表现,尤其是对噪声和遮挡具有更好的鲁棒性。具体操作就是:随机选择一个区域,然后采用随机值进行覆盖,模拟遮挡场景。 在细节上,可以通过参数控制擦除的面积比例和宽高比,如果随机到指定数目还无法满足设置条件,则强制返回。 一些可视化效果如下: Cutout 论文名称:Improved Regularization of Convolutional Neural Networks with Cutout...
Deep Learning
2026-03-02
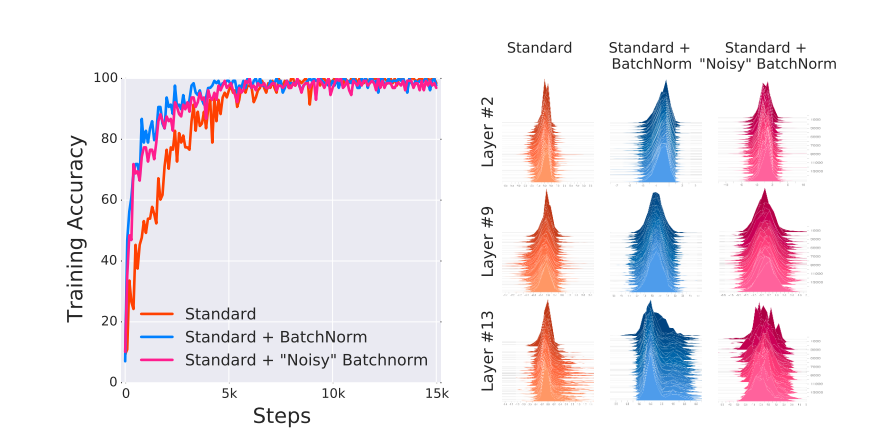
Batch Normalization 什么是批归一化(Batch Normalization) 以前在神经网络训练中,只是对输入层数据进行归一化处理,却没有在中间层进行归一化处理。要知道,虽然我们对输入数据进行了归一化处理,但是 输入数据经过 ** \(\sigma(WX+b)\) 这样的矩阵乘法以及非线性运算之后,其数据分布很可能被改变,而随着深度网络的多层运算之后,数据分布的变化将越来越大**。如果我们能在网络的中间也进行归一化处理,是否对网络的训练起到改进作用呢?答案是肯定的。 这种在神经网络中间层也进行归一化处理,使训练效果更好的方法,就是批归一化Batch Normalization(BN)。 其作用在整个mini-batch上,沿着 \(C\) 维度对 \(N,H,W\) 三个维度进行归一化。具体来说,就是把第1个样本的第1个通道,加上第2个样本第1个通道 ...... 加上第 \(N\) 个样本第1个通道,求平均,得到通道 1 的均值 (注意是除以 \(N×H×W\) 而不是单纯除以 \(N\) ,最后得到的是一个代表这个 batch...
Deep Learning
2026-03-02

通过卷积和池化等技术可以将图像进行降维,因此,一些研究人员也想办法恢复原分辨率大小的图像,特别是在语义分割领域应用很成熟。 Upsampling(上采样)[没有学习过程] 在FCN、U-net等网络结构中,涉及到了上采样。上采样概念: 上采样指的是任何可以让图像变成更高分辨率的技术 。最简单的方式是 重采样和插值 :将输入图片进行rescale到一个想要的尺寸,而且计算每个点的像素点,使用如双线性插值等插值方法对其余点进行插值来完成上采样过程。 在PyTorch中,上采样的层被封装在 torch.nn 中的 Vision Layers 里面,一共有4种: PixelShuffle Upsample UpsamplingNearest2d UpsamplingBilinear2d PixelShuffle 当stride = (1/r) < 1时,可以让卷积后的feature map变大——即分辨率变大,这个新的操作叫做sub-pixel convolution,具体原理可以看 “PixelShuffle:Real-Time Single Image and Video...
Deep Learning
2026-02-28
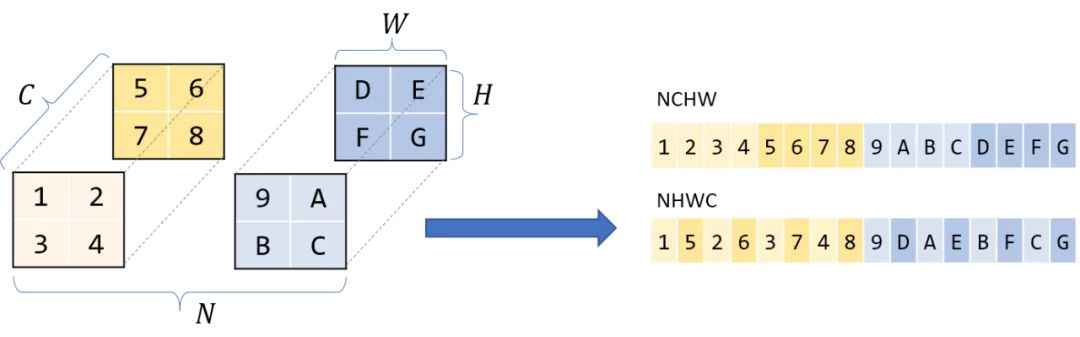
现代深度学习库对大多数操作都具有生产级的、高度优化的实现,这并不奇怪。但这些库究竟是什么魔法?他们如何能够将性能提高100倍?究竟怎样才能“优化”或加速神经网络的运行呢?在讨论高性能/高效DNNs时,我经常会问(也经常被问到)这些问题。 在这篇文章中,我将尝试带你了解在DNN库中卷积层是如何实现的。它不仅是在模型中最常见的和最重的操作,我还发现卷积高性能实现的技巧特别具有代表性——一点点算法的小聪明,非常多的仔细的调优和低层架构的开发。 我在这里介绍的很多内容都来自Goto等人的开创性论文:Anatomy of a high-performance matrix multiplication,该论文为OpenBLAS等线性代数库中使用的算法奠定了基础。 最原始的卷积实现 “过早的优化是万恶之源”——Donald Knuth 在进行优化之前,我们先了解一下基线和瓶颈。这是一个朴素的numpy/for循环卷积: '''
Convolve `input` with `kernel` to generate `output`
input.shape =...