
💡 GRPO相比PPO主要优势: 1. 训练更稳定 引入 KL 散度惩罚项,有效控制策略更新的幅度,避免策略崩溃,提高训练的稳定性 GRPO用组内相对优势替代value model,消除了value估计误差 通过组内归一化,自动消除reward scale和bias的影响 实验中发现GRPO的advantage方差比PPO小30%左右,训练崩溃率更低 2. 工程更简单 只需要1-2个模型(policy + reference),而PPO需要4个 显存占用减少50%以上,训练速度提升2-3倍 超参数更少,更容易调优 3. 相对奖励机制 通过对同一输入生成的多个输出进行比较,GRPO 能够更稳定地估计优势函数,减少了训练过程中的方差 背景 GRPO是 DeepSeek-Math model中提出的对PPO方法的改进策略: 强化学习(RL)在提升模型数学推理能力方面被证明是有效的 传统PPO算法需要较大训练资源 GRPO作为PPO的变体被提出,可以更高效地优化模型 PPO Vs GRPO PPO回顾 PPO的目标函数为: \[\begin{aligned}J_{PPO}(\theta) =...
Large Model
2026-03-10

问题背景 首先简化一下问题,本文所讨论的多模态,主要指图文混合的双模态,即输入和输出都可以是图文。可能有不少读者的第一感觉是:多模态模型难道不也是烧钱堆显卡,Transformer“一把梭”,最终“大力出奇迹”吗? 其实没那么简单。先看文本生成,事实上文本生成自始至终都只有一条主流路线,那就是语言模型,即建模条件概率 \(p(x_t|x_1,\cdots,x_{t-1})\) ,不论是最初的 n-gram语言模型,还是后来的Seq2Seq、GPT,都是这个条件概率的近似。也就是说,一直以来,人们对“实现文本生成需要往哪个方向走”是很明确的,只是背后所用的模型有所不同,比如LSTM、CNN、Attention乃至最近复兴的线性RNN等。所以, 文本生成确实可以All in Transformer来大力出奇迹,因为方向是标准的、清晰的。 然而,对于图像生成,并没有这样的“标准方向”。就本站所讨论过的图像生成模型,就有 VAE 、 GAN 、 Flow 、 Diffusion ,还有小众的 EBM...
Large Model
2026-03-10

k1.5—CoT强化训练 概述 Kimi k1.5采用了一种简化而有效的强化学习框架,其核心在于长上下文扩展和改进的策略优化方法,而不依赖于更复杂的技术如蒙特卡洛树搜索、价值函数和过程奖励模型。 问题设定 给定训练数据集 \(D = \{(x_i, y^*_i)\}_{i=1}^n\) ,其中包含问题 \(x_i\) 和对应的真实答案 \(y^*_i\) ,目标是训练一个策略模型 \(\pi_\theta\) 来准确解决测试问题。在复杂推理场景中,思维链(CoT)方法提出使用一系列中间步骤 \(z = (z_1, z_2, ..., z_m)\) 来连接问题 \(x\) 和答案 \(y\) ,每个 \(z_i\) 是解决问题的重要中间步骤。 当解决问题 \(x\) 时,思维 \(z_t \sim \pi_\theta(\cdot|x, z_1, ..., z_{t-1})\) 被自回归采样,最终答案 \(y \sim \pi_\theta(\cdot|x, z_1, ..., z_m)\) 。 强化学习目标 基于真实答案 \(y^*\) ,分配一个值 \(r(x, y, y^*)...
Generative Model
2026-03-04

SD模型原理 SD是CompVis、Stability AI和LAION等公司研发的一个文生图模型,它的模型和代码是开源的,而且训练数据LAION-5B也是开源的。SD在开源90天github仓库就收获了 33K的stars ,可见这个模型是多受欢迎。 SD是一个 基于latent的扩散模型 ,它在UNet中引入text condition来实现基于文本生成图像。SD的核心来源于 Latent Diffusion 这个工作,常规的扩散模型是基于pixel的生成模型,而Latent Diffusion是基于latent的生成模型,它先采用一个autoencoder将图像压缩到latent空间,然后用扩散模型来生成图像的latents,最后送入autoencoder的decoder模块就可以得到生成的图像。 基于latent的扩散模型的优势在于计算效率更高效,因为图像的latent空间要比图像pixel空间要小,这也是SD的核心优势...
Generative Model
2026-03-04

简介 如果以概率的视角看待世界的生成模型。 在这样的世界观中,我们可以将任何类型的观察数据(例如 \(D\) )视为来自底层分布(例如 \( p_{data}\) )的有限样本集。 任何生成模型的目标都是在访问数据集 \(D\) 的情况下近似该数据分布。 如果我们能够学习到一个好的生成模型,我们可以将学习到的模型用于下游推理。 我们主要对数据分布的参数近似感兴趣,在一组有限的参数中,它总结了关于数据集 \(D\) 的所有信息。 与非参数模型相比,参数模型在处理大型数据集时能够更有效地扩展,但受限于可以表示的分布族。 在参数的设置中,我们可以将学习生成模型的任务视为在模型分布族中挑选参数,以最小化模型分布和数据分布之间的距离。 如上图,给定一个狗的图像数据集,我们的目标是学习模型族 \(M\) 中生成模型 θ 的参数,使得模型分布 \(p_θ\) 接近 \(p_{data}\) 上的数据分布。 在数学上,我们可以将我们的目标指定为以下优化问题: \[\mathop{min}\limits_{\theta\in M}d(p_\theta,p_{data})\] 其中, \(d()\)...
Generative Model
2026-03-04
Score based generative model SMLD的关键点: 以多个不同量级的噪声对数据进行扰动,并训练一个分数网络来估计不同噪声下的分数 加噪的量级有大有小,都是在原始数据上进行加噪,最终的分布趋向于 $\mathcal{N}(0,max_i{\sigma_i^2})$ 运用分数匹配的方式来训练基于U-Net结构的MCSN网络, 使得MCSN能够估计任意加噪后分布的分数 基于任意加噪分布的分数和退火的郎之万动力学应用到采样来生成准确的原始数据分布的新样本 正式开始介绍之前首先解答一下这个问题: score-based 模型是什么东西,微分方程在这个模型里到底有什么用? 我们知道生成模型基本都是从某个现有的分布中进行采样得到生成的样本,为此模型需要完成对分布的建模。根据建模方式的不同可以分为隐式建模(例如 GAN、diffusion models)和显式建模(例如 VAE、normalizing flows)。和上述的模型相同,score-based 模型也是用一定方式对分布进行了建模。具体而言,这类模型建模的对象是概率分布函数 log 的梯度,也就是 score...
Generative Model
2026-03-04
技术分析 从方法上来看,条件控制生成的方式分两种: 事后修改(Classifier-Guidance)和事前训练(Classifier-Free) 。 对于大多数人来说,一个SOTA级别的扩散模型训练成本太大了,而分类器(Classifier)的训练还能接受,所以就想着直接复用别人训练好的无条件扩散模型,用一个分类器来调整生成过程以实现控制生成,这就是事后修改的Classifier-Guidance方案;而对于“财大气粗”的Google、OpenAI等公司来说,它们不缺数据和算力,所以更倾向于往扩散模型的训练过程中就加入条件信号,达到更好的生成效果,这就是事前训练的Classifier-Free方案。 Classifier-Guidance方案最早出自 《Diffusion Models Beat GANs on Image Synthesis》 ,最初就是用来实现按类生成的;后来 《More Control for Free! Image Synthesis with Semantic Diffusion Guidance》...
Generative Model
2026-03-04
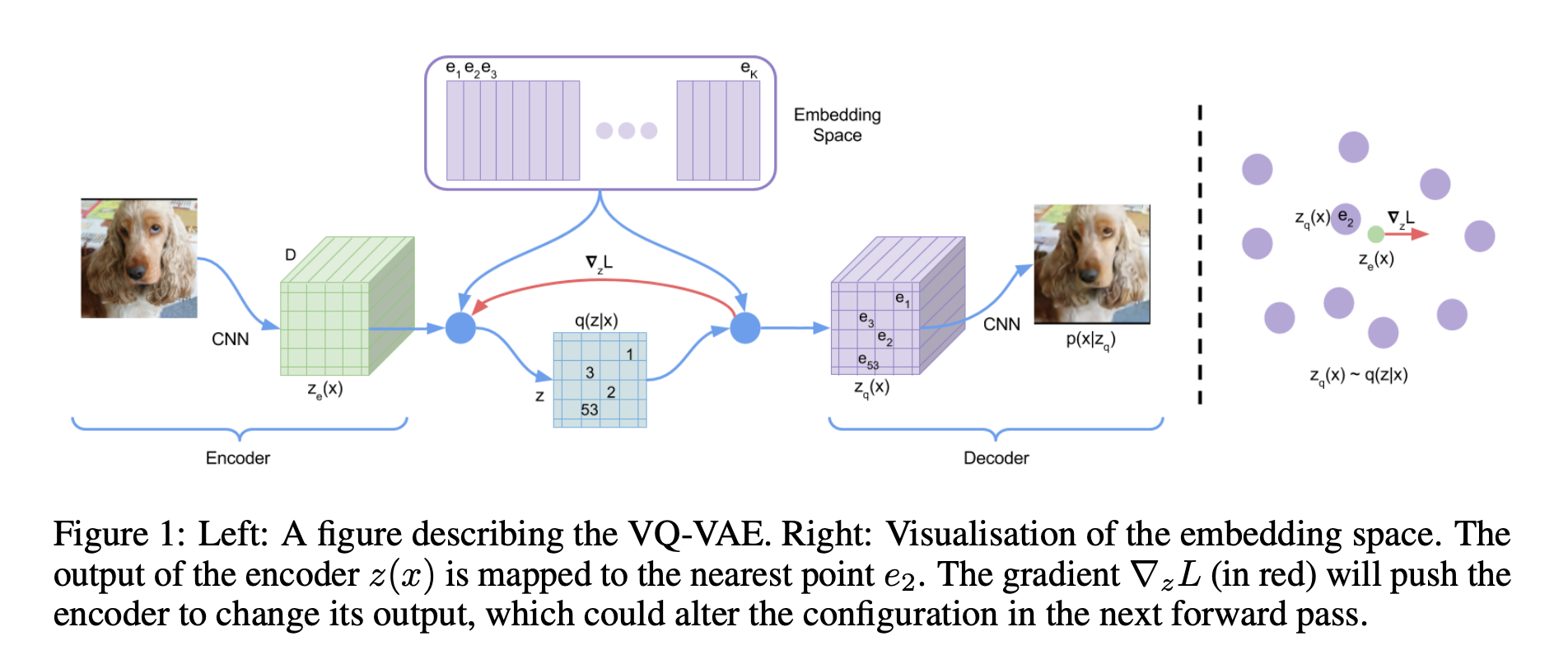
简介 作为一个自编码器,VQ-VAE的一个明显特征是它编码出的编码向量是离散的,换句话说, 它最后得到的编码向量的每个元素都是一个整数 ,这也就是“Quantised”的含义,我们可以称之为“量子化”(跟量子力学的“量子”一样,都包含离散化的意思)。 明明整个模型都是连续的、可导的,但最终得到的编码向量却是离散的,并且重构效果看起来还很清晰(如文章开头的图),这至少意味着VQ-VAE会包含一些有意思、有价值的技巧,值得我们学习一番。 首先, VQ-VAE其实就是一个AE(自编码器)而不是VAE(变分自编码器) ,我不知道作者出于什么目的非得用概率的语言来沾VAE的边,这明显加大了读懂这篇论文的难度。其次,VQ-VAE的核心步骤之一是Straight-Through Estimator,这是将引变量离散化后的优化技巧,在原论文中没有稍微详细的讲解,以至于必须看源码才能更好地知道它说啥。最后,论文的核心思想也没有很好地交代清楚,给人的感觉是纯粹在介绍模型本身而没有介绍模型思想。 PixelCNN...
Generative Model
2026-03-04

Flow Matching 其实是将 flow 的离散形式转换为连续形式(连续标准化流CNF),进而可以看成是一个ODE方程,实际求解的是这个ODE 求解的核心思路是:构建速度场通过数值积分求解位移,也就是通过预测速度场,从而转为ode求解 从概率路径的角度上来说,解是无穷多的,不同的方法本质上讲是在于构造尽可能简单、直接、易解的概率路径 通过不同的条件概率路径,可以构造出VP(score matching)、 VE(diffusion)、OT(1-rectified flow)等形式 实际的边缘概率分布路径并不是一条直线 ,我们是通过拟合条件速度场来逼近边缘速度场, 即使我们证明了对于参数 \(\theta\) 来说优化目标是等价的,但终究还是有一些gap Flow-based Models Normalizing Flow Normalizing Flow 是一种基于 变换 对概率分布进行建模的模型,其通过一系列 离散且可逆的变换 实现任意分布与先验分布(例如标准高斯分布)之间的相互转换。在 Normalizing Flow...
Generative Model
2026-03-04

精巧的flow 不得不说,flow模型是一个在设计上非常精巧的模型。总的来看,flow就是想办法得到一个encoder将输入 𝑥 编码为隐变量 𝑧,并且使得 𝑧 服从标准正态分布。 得益于flow模型的精巧设计,这个encoder是可逆的,从而我们可以立马从encoder写出相应的decoder(生成器)出来,因此,只要encoder训练完成,我们就能同时得到decoder,完成生成模型的构建 。 为了完成这个构思,不仅仅要使得模型可逆,还要使得对应的雅可比行列式容易计算,为此,NICE提出了加性耦合层,通过多个加性耦合层的堆叠,使得模型既具有强大的拟合能力,又具有单位雅可比行列式。就这样,一种不同于VAE和GAN的生成模型——flow模型就这样出来了,它通过巧妙的构造,让我们能直接去拟合概率分布本身。 待探索的空间...
Generative Model
2026-03-04

Diffusion Models from SDE 连续扩散模型 (Continuous Diffusion Models) 将传统的离散时间扩散过程扩展到连续时间域,可以被视为一个随机过程,使用随机微分方程(SDE)来描述。其前向过程可以写成如下形式: \[\mathrm d\mathbf x=\mathbf f(\mathbf x,t)\mathrm dt+g(t)\mathrm d\mathbf w\tag{1}\] 其中, \(f(x,t)\) 可以看成偏移系数, \(g(t)\) 可以看成是扩散系数, \(dw\) 是标准布朗运动。这个SDE 描述了数据在连续时间域内如何被噪声逐渐破坏。 这个随机过程的 逆向过程 存在(更准确的描述:下面的逆向时间SDE具有 与正向过程SDE相同的联合分布 )为 \[d\mathbf{x}=[\mathbf{f}(\mathbf{x},t)-g^2(t)\nabla_{\mathbf{x}}\log p_t(\mathbf{x})]dt+g(t)d\bar{\mathbf{w}}\tag{2}\]...
Generative Model
2026-03-04

DDPM 有一个非常明显的问题:采样过程很慢。因为 DDPM 的反向过程利用了马尔可夫假设, 所以每次都必须在相邻的时间步之间进行去噪,而不能跳过中间步骤 。原始论文使用了 1000 个时间步,所以我们在采样时也需要循环 1000 次去噪过程,这个过程是非常慢的。 为了加速 DDPM 的采样过程,DDIM 在不利用马尔可夫假设的情况下推导出了 diffusion 的反向过程,最终可以实现仅采样 20~100 步的情况下达到和 DDPM 采样 1000 步相近的生成效果,也就是提速 10~50 倍。这篇文章将对 DDIM 的理论进行讲解,并实现 DDIM 采样的代码。 DDPM 的反向过程 首先我们回顾一下 DDPM 反向过程的推导,为了推导出 \(q(\mathbf{x}_{t-1}|\mathbf{x}_t)\) 这个条件概率分布,DDPM 利用贝叶斯公式将其变成了先验分布的组合, 并且通过向条件中加入 \(\mathbf{x}_0 \) 将所有的分布转换为已知分布 :...