
💡 GRPO相比PPO主要优势: 1. 训练更稳定 引入 KL 散度惩罚项,有效控制策略更新的幅度,避免策略崩溃,提高训练的稳定性 GRPO用组内相对优势替代value model,消除了value估计误差 通过组内归一化,自动消除reward scale和bias的影响 实验中发现GRPO的advantage方差比PPO小30%左右,训练崩溃率更低 2. 工程更简单 只需要1-2个模型(policy + reference),而PPO需要4个 显存占用减少50%以上,训练速度提升2-3倍 超参数更少,更容易调优 3. 相对奖励机制 通过对同一输入生成的多个输出进行比较,GRPO 能够更稳定地估计优势函数,减少了训练过程中的方差 背景 GRPO是 DeepSeek-Math model中提出的对PPO方法的改进策略: 强化学习(RL)在提升模型数学推理能力方面被证明是有效的 传统PPO算法需要较大训练资源 GRPO作为PPO的变体被提出,可以更高效地优化模型 PPO Vs GRPO PPO回顾 PPO的目标函数为: \[\begin{aligned}J_{PPO}(\theta) =...
NLP
2026-03-26

概述 众所周知,尽管基于Attention机制的Transformer类模型有着良好的并行性能,但它的空间和时间复杂度都是 \(\mathcal{O}(n^2)\) 级别的, \(n\) 是序列长度,所以当 \(n\) 比较大时Transformer模型的计算量难以承受。近来,也有不少工作致力于降低Transformer模型的计算量,比如模型剪枝、量化、蒸馏等精简技术,又或者修改Attention结构,使得其复杂度能降低到 \(\mathcal{O}(n\log n)\) 甚至 \(\mathcal{O}(n)\) 。 改变这一复杂度的思路主要有两种: 一是走稀疏化的思路,比如OpenAI的 Sparse Attention ,通过“只保留小区域内的数值、强制让大部分注意力为零”的方式,来减少Attention的计算量。经过特殊设计之后,Attention矩阵的大部分元素都是0,因此理论上它也能节省显存占用量和计算量。后续类似工作还有 《Explicit Sparse Transformer: Concentrated Attention Through Explicit...
NLP
2026-03-26

Attention 当前最流行的Attention机制当属 Scaled-Dot Attention,形式为 \[\begin{equation}Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}) = softmax\left(\boldsymbol{Q}\boldsymbol{K}^{\top}\right)\boldsymbol{V}\tag{1}\end{equation}\] 这里的 \(\boldsymbol{Q}\in\mathbb{R}^{n\times d_k}, \boldsymbol{K}\in\mathbb{R}^{m\times d_k}, \boldsymbol{V}\in\mathbb{R}^{m\times d_v}\) ,简单起见我们就没显式地写出Attention的缩放因子了。本文我们主要关心Self Attention场景,所以为了介绍上的方便统一设 \(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V}\in\mathbb{R}^{n\times...
Attention 当前最流行的Attention机制当属 Scaled-Dot Attention,形式为 \[\begin{equation}Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}) = softmax\left(\boldsymbol{Q}\boldsymbol{K}^{\top}\right)\boldsymbol{V}\tag{1}\end{equation}\] 这里的 \(\boldsymbol{Q}\in\mathbb{R}^{n\times d_k}, \boldsymbol{K}\in\mathbb{R}^{m\times d_k}, \boldsymbol{V}\in\mathbb{R}^{m\times d_v}\) ,简单起见我们就没显式地写出Attention的缩放因子了。本文我们主要关心Self Attention场景,所以为了介绍上的方便统一设 \(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V}\in\mathbb{R}^{n\times...
NLP
2026-03-26

概述 SSM的概念由来已久,但这里我们特指深度学习中的SSM,一般认为其开篇之作是2021年的 S4 ,不算太老,而SSM最新最火的变体大概是 Mamba 。当然,当我们谈到SSM时,也可能泛指一切线性RNN模型,这样 RWKV 、 RetNet 还有此前LRU都可以归入此类。不少SSM变体致力于成为Transformer的竞争者,尽管笔者并不认为有完全替代的可能性,但SSM本身优雅的数学性质也值得学习一番。 尽管我们说SSM起源于S4,但在S4之前,SSM有一篇非常强大的奠基之作 《HiPPO: Recurrent Memory with Optimal Polynomial Projections》 (简称HiPPO),所以本文从HiPPO开始说起。 另外值得一提的是,SSM代表作HiPPO、S4、Mamba的一作都是 Albert Gu ,他还有很多篇SSM相关的作品,毫不夸张地说,这些工作筑起了SSM大厦的基础。不论SSM前景如何,这种坚持不懈地钻研同一个课题的精神都值得我们由衷地敬佩。 今天,基本上你能叫出的任何语言模型都是 Transformer 模型。OpenAI 的...
NLP
2026-03-25

概述 本文模型脉络图 本文介绍一个比较有意思的高效Transformer工作——来自Google的 《Transformer Quality in Linear Time》 , 什么样的结果值得我们用“惊喜”来形容?有没有言过其实?我们不妨先来看看论文做到了什么: 提出了一种新的Transformer变体,它依然具有二次的复杂度,但是相比标准的Transformer,它有着更快的速度、更低的显存占用以及更好的效果; 提出一种新的线性化Transformer方案,它不但提升了原有线性Attention的效果,还保持了做Decoder的可能性,并且做Decoder时还能保持高效的训练并行性。 说实话,笔者觉得做到以上任意一点都是非常难得的,而这篇论文一下子做到了两点,所以我愿意用“惊喜满满”来形容它。更重要的是,论文的改进总的来说还是比较自然和优雅的,不像很多类似工作一样显得很生硬。此外,笔者自己也做了简单的复现实验,结果显示论文的可复现性应该是蛮好的,所以真的有种“Transformer危矣”的感觉了。 门控注意(Gated Attention Unit)...
NLP
2026-03-25

Attention 当前最流行的Attention机制当属 Scaled-Dot Attention,形式为 \[Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}) = softmax\left(\boldsymbol{Q}\boldsymbol{K}^{\top}\right)\boldsymbol{V}\tag{1}\] 这里的 \(\boldsymbol{Q}\in\mathbb{R}^{n\times d_k}, \boldsymbol{K}\in\mathbb{R}^{m\times d_k}, \boldsymbol{V}\in\mathbb{R}^{m\times d_v}\) ,简单起见我们就没显式地写出Attention的缩放因子了。本文我们主要关心Self Attention场景,所以为了介绍上的方便统一设 \(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V}\in\mathbb{R}^{n\times d}\) ,一般场景下都有 \(n > d\) 甚至...
Machine Learning
2026-03-19
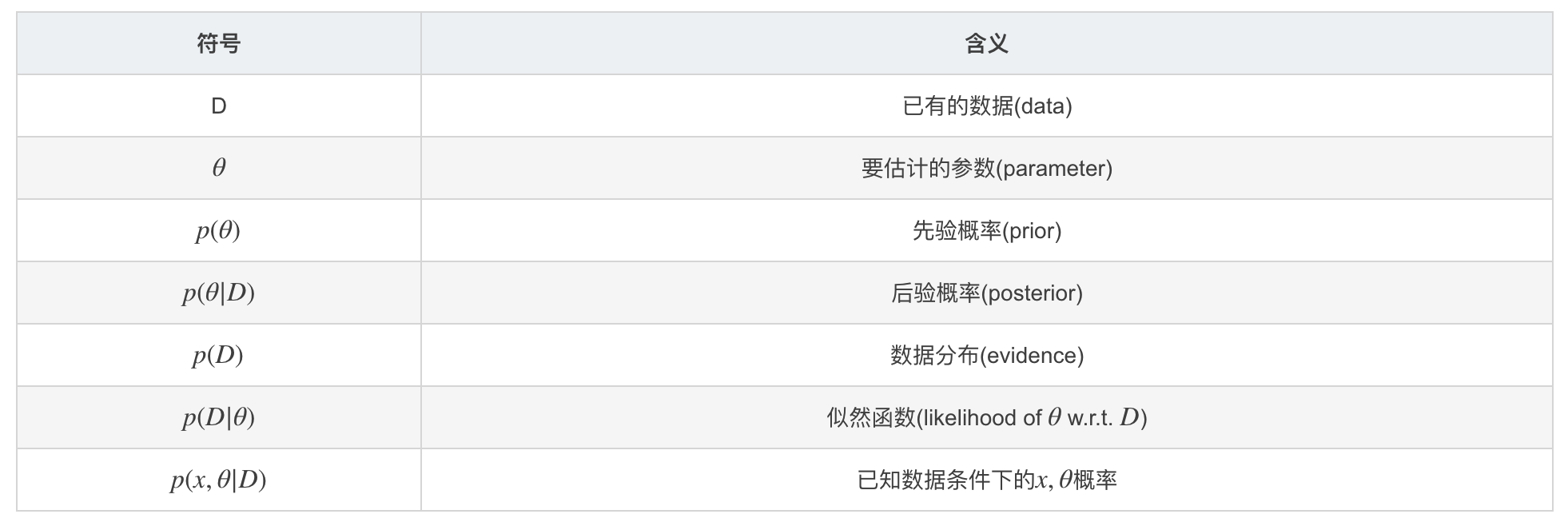
序言 极大似然估计与贝叶斯估计是统计中两种对模型的参数确定的方法,两种参数估计方法使用不同的思想。 前者来自于频率派,认为参数是固定的,我们要做的事情就是根据已经掌握的数据来估计这个参数;而后者属于贝叶斯派,认为参数也是服从某种概率分布的,已有的数据只是在这种参数的分布下产生的。 所以,直观理解上,极大似然估计就是假设一个参数 \(θ\) ,然后根据数据来求出这个 \(θ\) . 而贝叶斯估计的难点在于 \(p(θ)\) 需要人为设定,之后再考虑结合MAP(maximum a posterior)方法来求一个具体的 \(θ\) . 所以极大似然估计与贝叶斯估计最大的不同就在于是否考虑了先验,而两者适用范围也变成了:极大似然估计适用于数据大量,估计的参数能够较好的反映实际情况;而贝叶斯估计则在数据量较少或者比较稀疏的情况下,考虑先验来提升准确率。 预知识 为了更好的讨论,本节会先给出我们要解决的问题,然后给出一个实际的案例。这节不会具体涉及到极大似然估计和贝叶斯估计的细节,但是会提出问题和实例,便于后续方法理解。 问题前提 首先,我们有一堆数据...
Machine Learning
2026-03-19
k-d树(k-dimensional树的简称),是一种分割k维数据空间的数据结构。主要应用于 多维空间关键数据的搜索 (如:范围搜索和最近邻搜索)。 应用背景 SIFT算法中做特征点匹配的时候就会利用到k-d树。而特征点匹配实际上就是一个通过距离函数在高维矢量之间进行相似性检索的问题。针对如何快速而准确地找到查询点的近邻,现在提出了很多高维空间索引结构和近似查询的算法,k-d树就是其中一种。 索引结构中相似性查询有两种基本的方式:一种是范围查询(range searches),另一种是K近邻查询(K-neighbor searches)。范围查询就是给定查询点和查询距离的阈值,从数据集中找出所有与查询点距离小于阈值的数据;K近邻查询是给定查询点及正整数K,从数据集中找到距离查询点最近的K个数据,当K=1时,就是最近邻查询(nearest neighbor searches)。...
Machine Learning
2026-03-19
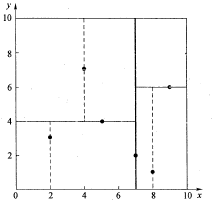
PCA PCA的思想 PCA顾名思义,就是找出数据里最主要的方面,用数据里最主要的方面来代替原始数据。具体的,假如我们的数据集是 \(n\) 维的,共有 \(m\) 个数据 \((𝑥(1),𝑥(2),...,𝑥(𝑚))\) 。我们希望将这 \(m\) 个数据的维度从 \(n\) 维降到 \(n'\) 维,希望这 \(m\) 个 \(n'\) 维的数据集尽可能的代表原始数据集。我们知道数据从 \(n\) 维降到 \(n'\) 维肯定会有损失,但是我们希望损失尽可能的小。那么如何让这 \(n'\) 维的数据尽可能表示原来的数据呢? 我们先看看最简单的情况,也就是 \(n=2\) , \(n'=1\) ,也就是将数据从二维降维到一维。数据如下图。我们希望找到某一个维度方向,它可以代表这两个维度的数据。图中列了两个向量方向, \(u_1\) 和 \(𝑢_2\) ,那么哪个向量可以更好的代表原始数据集呢?从直观上也可以看出, \(𝑢_1\) 比 \(𝑢_2\) 好。 为什么 \(𝑢_1\) 比 \(𝑢_2\)...
Machine Learning
2026-03-18
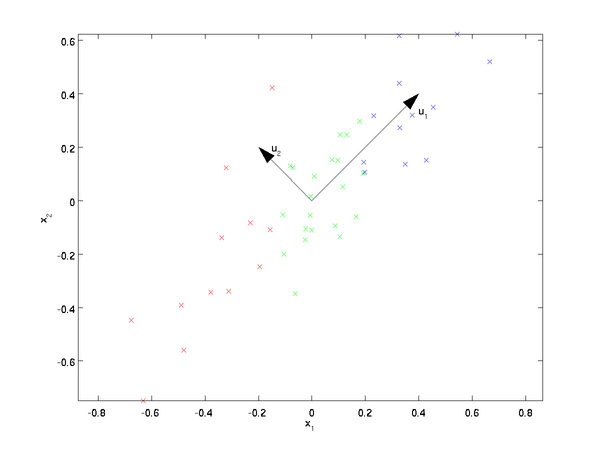
模型介绍 Logistic Regression 虽然被称为回归,但其实际上是分类模型,并常用于二分类。Logistic Regression 因其简单、可并行化、可解释强深受工业界喜爱。 Logistic 回归的本质是:假设数据服从这个分布,然后使用极大似然估计做参数的估计。 Logistic 分布 Logistic 分布是一种连续型的概率分布,其 分布函数 和 密度函数 分别为: \[F(x)=P(X\le x)=\frac{1}{1+e^{-(x-\mu)/\gamma}}\\ f(x)=F^{'}(x)=\frac{e^{-(x-\mu)/\gamma}}{\gamma(1+e^{-(x-\mu)/\gamma})^2}\] 其中, \(\mu\) 表示位置参数, \(\gamma\) 为形状参数。我们可以看下其图像特征: Logistic 分布是由其位置和尺度参数定义的连续分布。Logistic 分布的形状与正态分布的形状相似,但是 Logistic 分布的尾部更长,所以我们可以使用 Logistic...
Machine Learning
2026-03-18
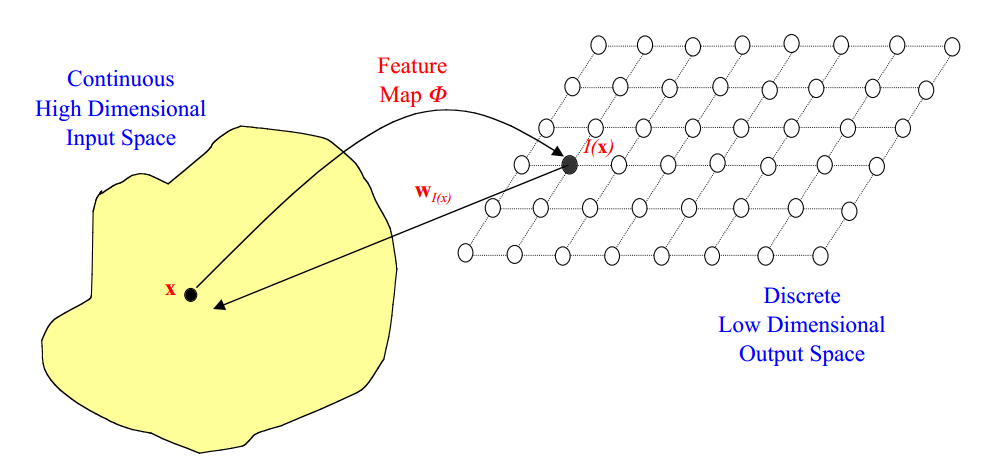
什么是自组织映射? 一个特别有趣的无监督系统是基于 竞争性学习 ,其中输出神经元之间竞争激活,结果是在任意时间只有一个神经元被激活。这个激活的神经元被称为 胜者神经元(winner-takes-all neuron) 。这种竞争可以通过在神经元之间具有 横向抑制连接 (负反馈路径)来实现。其结果是神经元被迫对自身进行重新组合,这样的网络我们称之为 自组织映射(Self Organizing Map,SOM) 。 拓扑映射 神经生物学研究表明,不同的感觉输入(运动,视觉,听觉等)以 有序的方式 映射到大脑皮层的相应区域。 这种映射我们称之为 拓扑映射 ,它具有两个重要特性: 在表示或处理的每个阶段,每一条传入的信息都保存在适当的上下文(相邻节点)中 处理密切相关的信息的神经元之间保持密切,以便它们可以通过短突触连接进行交互 我们的兴趣是建立人工的拓扑映射,以神经生物学激励的方式通过自组织进行学习。 我们将遵循 拓扑映射形成的原则 :“拓扑映射中输出层神经元的空间位置对应于输入空间的特定域或特征”。 建立自组织映射 SOM的主要目标是将任意维度的输入信号模式 转换...