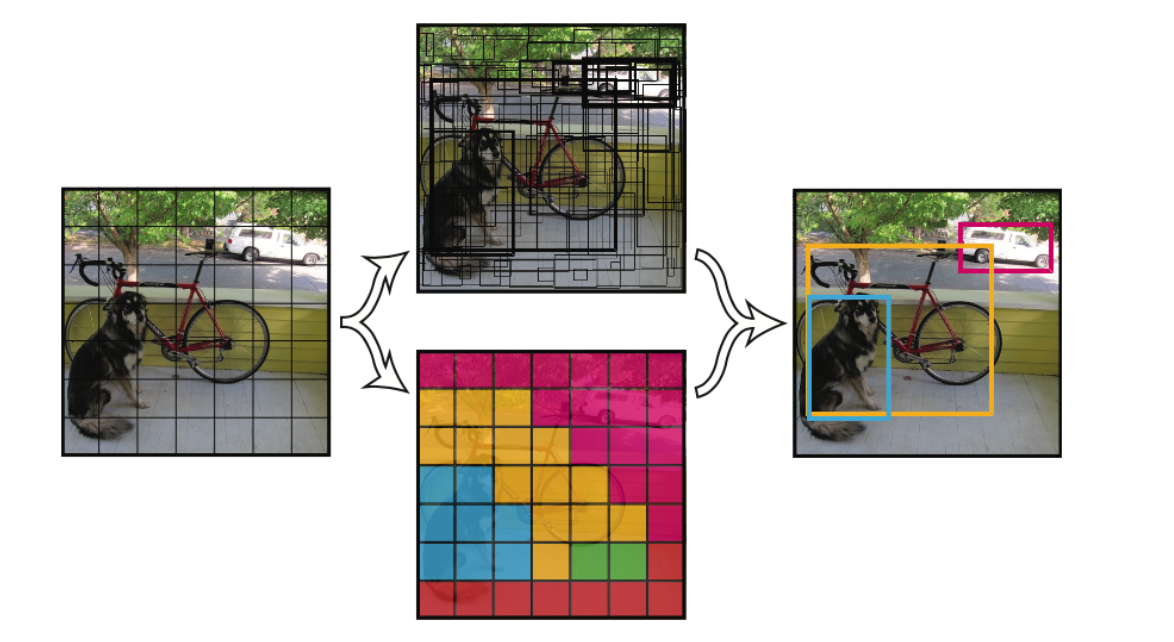
Computer Vision
2026-04-15
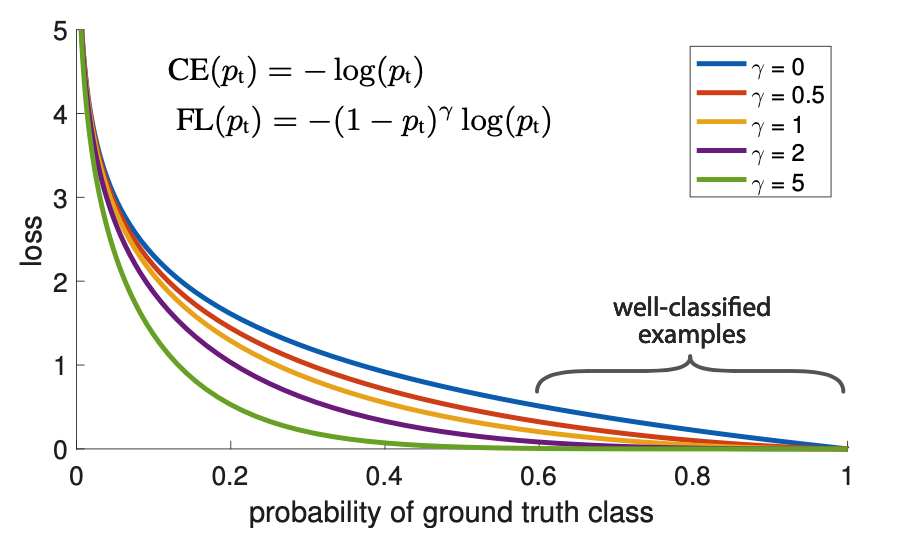
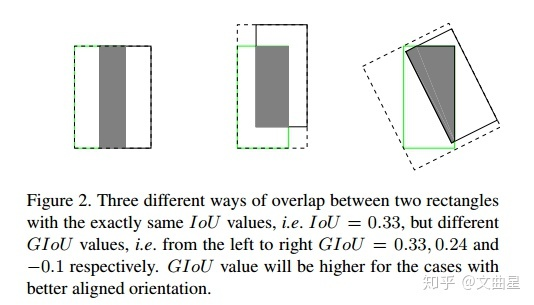
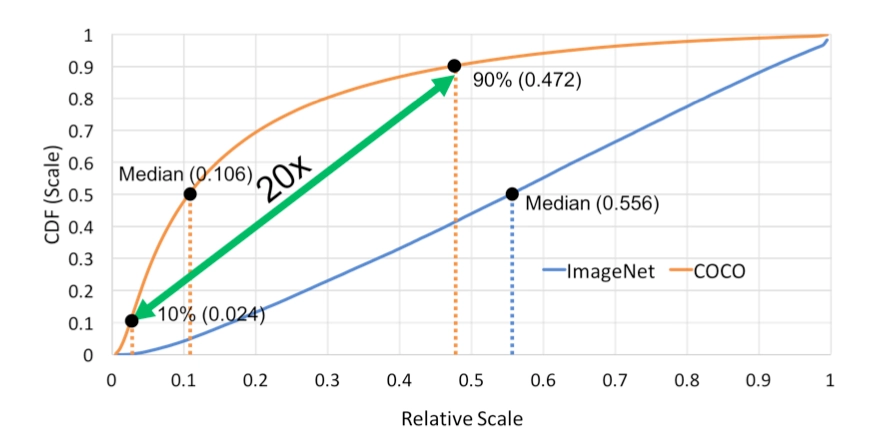
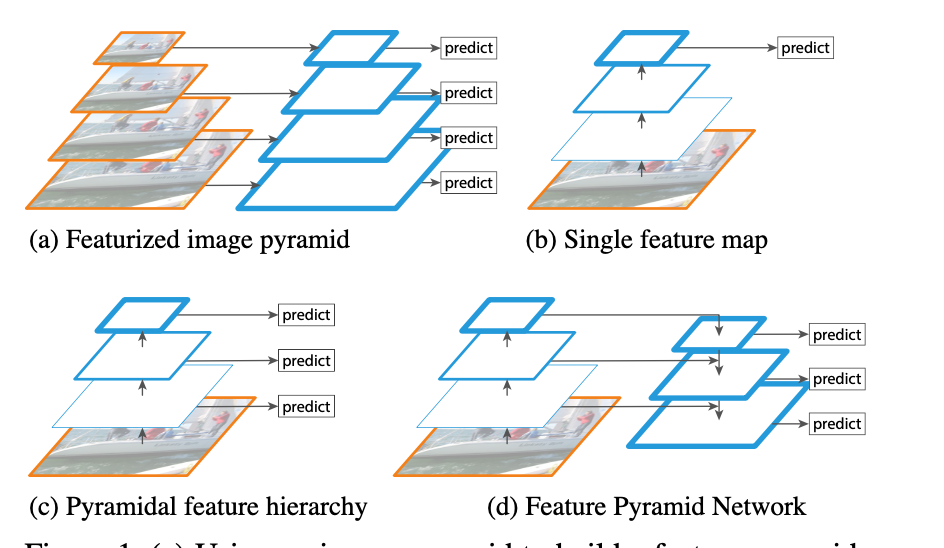
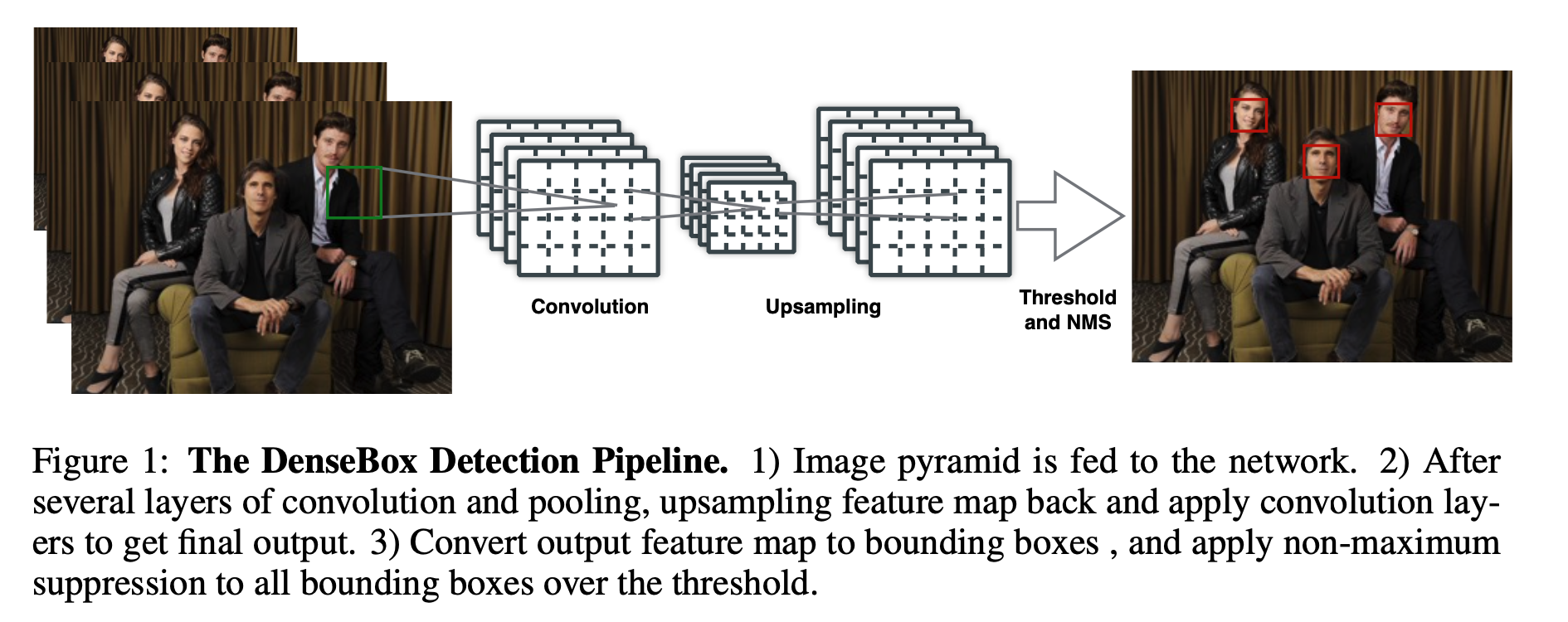
Focal Loss 在早期的目标检测中,最头疼的问题是 正负样本极度不平衡 (背景太多,物体太少),且大量背景是“容易分类的负样本”。传统的交叉熵损失(BCE)会被这些海量的简单样本淹没。 为了解决这个问题,Focal Loss (FL) 引入了一个动态缩放因子: 对于正样本,损失大致为: \(-(1-p)^\gamma \log(p)\) 核心逻辑: 如果模型已经预测得很准了(概率 \(p\) 接近 \(1\) ),那么 \((1−p)^\gamma\) 就会趋近于 \(0\) ,从而 降低简单样本的权重 ,强迫模型去关注那些还没学好的“困难样本”。 focal loss 形式如下 \[\text{FL}(p,y) = \begin{cases} -\alpha(1-p)^\gamma log(p) & y = 1 \\ -(1-\alpha)p^\gamma log(1-p) & y=0 \end{cases}\tag{1}\] 详情参考: Focal Loss & RetinaNet GFL(Generalized Focal Loss) 论文地址:...