128. 最长连续序列 题目 给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。 请你设计并实现时间复杂度为 O(n) 的算法解决此问题。 示例 1: 输入:nums = [100,4,200,1,3,2]
输出:4
解释:最长数字连续序列是 [1, 2, 3, 4]。它的长度为 4。 示例 2: 输入:nums = [0,3,7,2,5,8,4,6,0,1]
输出:9 示例 3: 输入:nums = [1,0,1,2]
输出:3 提示: 0 <= nums.length <= 10 5 -10 9 <= nums[i] <= 10 9 题解 我们需要在 \(O(1)\) 的时间内查找某个数是否存在。因此,首先将数组中的所有元素放入一个 HashSet 中。这不仅能去重,还能支持快速查找。 避免冗余计算 (关键优化) 如果我们对集合中的每一个数都尝试去向后计数(例如,对于 x ,尝试找 x+1 , x+2 ...),最坏情况下的时间复杂度会退化到 \(O(n^2)\) 。 优化策略 : 我们 只从序列的起点开始计数 。...
76. 最小覆盖子串 题目 给定两个字符串 s 和 t ,长度分别是 m 和 n ,返回 s 中的 最短窗口 子串 ,使得该子串包含 t 中的每一个字符( 包括重复字符 )。如果没有这样的子串,返回空字符串 "" 。 测试用例保证答案唯一。 示例 1: 输入:s = "ADOBECODEBANC", t = "ABC"
输出:"BANC"
解释:最小覆盖子串 "BANC" 包含来自字符串 t 的 'A'、'B' 和 'C'。 示例 2: 输入:s = "a", t = "a"
输出:"a"
解释:整个字符串 s 是最小覆盖子串。 示例 3: 输入: s = "a", t = "aa"
输出: ""
解释: t 中两个字符 'a' 均应包含在 s 的子串中,
因此没有符合条件的子字符串,返回空字符串。 提示: m == s.length n == t.length 1 <= m, n <= 10 5 s 和 t 由英文字母组成 题解 这是一个经典的 滑动窗口 (Sliding Window) 问题 我们需要维护一个动态的窗口 [left, right] : 右移扩大 :不断移动...
Computer Vision
2026-01-11

在正式介绍之前,先简单回顾一下现有的两大类方法。第一大类,也是从非Deep时代,乃至CV初期就被就被广泛使用的方法叫做image pyramid。在image pyramid中,我们直接对图像进行不同尺度的缩放,然后将这些图像直接输入到detector中去进行检测。虽然这样的方法十分简单,但其效果仍然是最佳,也后续启发了SNIP这一系列的工作。单论性能而言,multiscale training/testing仍然是一个不可缺少的组件。然而其缺点也是很明显的,测试时间大幅度提高,对于实际使用并不友好。 另外一大类方法,也是Deep方法所独有的,也就是feature pyramid。最具代表性的工作便是经典的FPN了。这一类方法的思想是直接在feature层面上来近似image pyramid...
Computer Vision
2026-01-11
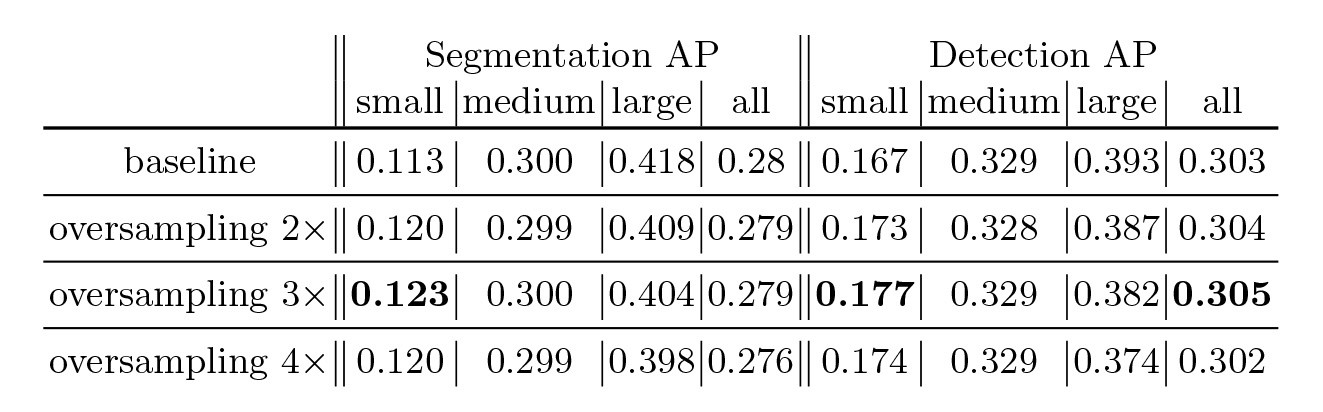
在深度学习目标检测中,特别是人脸检测中,由于分辨率低、图像模糊、信息少、噪声多,小目标和小人脸的检测一直是一个实用和常见的难点问题。然而,在过去几年的发展中,也出现了一些提高小目标检测性能的解决方案。本文将对这些方法进行分析、整理和总结。 图像金字塔和多尺度滑动窗口检测 一开始,在深学习方法成为流行之前,对于不同尺度的目标,通常是从原始图像开始,使用不同的分辨率构建图像金字塔,然后使用分类器对金字塔的每一层进行滑动窗口的目标检测。 在著名的人脸检测器MTCNN中,使用图像金字塔法检测不同分辨率的人脸目标。然而,这种方法通常是缓慢的,虽然构建图像金字塔可以使用卷积核分离加速或简单粗暴地缩放,但仍需要做多个特征提取,后来有人借其想法想出一个特征金字塔网络FPN,在不同层融合特征,只需要一次正向计...
Computer Vision
2026-01-11
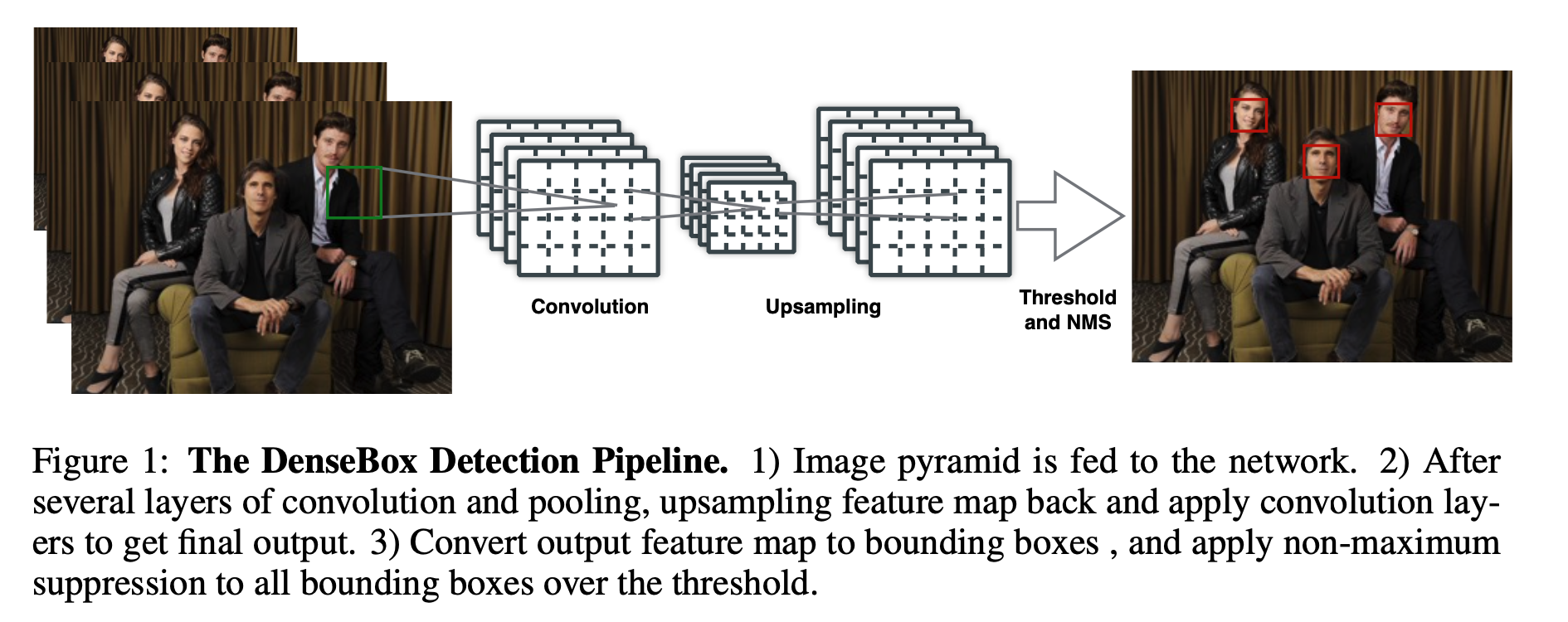
简介 "Anchorfree"(无锚点)是一种目标检测方法,与传统的使用锚框(anchor boxes)的方法(例如Faster RCNN)不同。在传统方法中,锚框是预先定义的、具有不同尺寸和长宽比的矩形区域,用于捕捉不同尺寸和形状的目标。而在"anchorfree"方法中,不再使用锚框,而是直接预测目标的位置和形状,通常使用网络输出的热图和偏移信息。 以下是对"anchorfree"方法的一些关键理解点: 无需预定义锚框: 在传统目标检测方法中,需要事先定义和生成一组锚框,这可能需要大量的人工工作。而在"anchorfree"方法中,不再需要锚框,模型可以自动学习目标的位置和形状。 直接位置和形状回归: "anchorfree"方法通过输出的热图来表示目标的存在概率,并使用偏移信息来定位目...
Computer Vision
2026-01-11
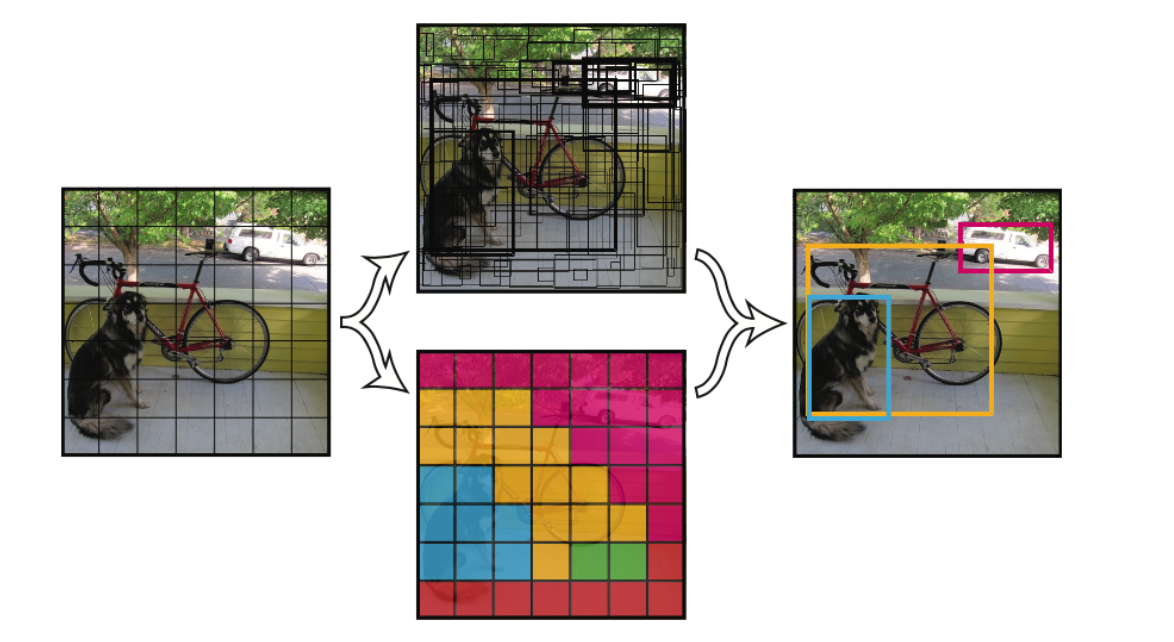
YOLO的核心思想就是利用整张图作为网络的输入,直接在输出层回归bounding box的位置和bounding box所属的类别。 faster RCNN中也直接用整张图作为输入,但是fasterRCNN整体还是采用了RCNN那种 proposal+classifier的思想,只不过是将提取proposal的步骤放在CNN中实现了,而YOLO则采用直接回归的思路。 YOLO v1 将一幅图像分成SxS个网格(grid cell),如果某个object的中心 落在这个网格中,则这个网格就负责预测这个object。 每个网格要预测B个bounding box,每个bounding box除了要回归自身的位置之外,还要附带预测一个confidence值。 这个confidence代表了所预测的b...
Computer Vision
2026-01-11
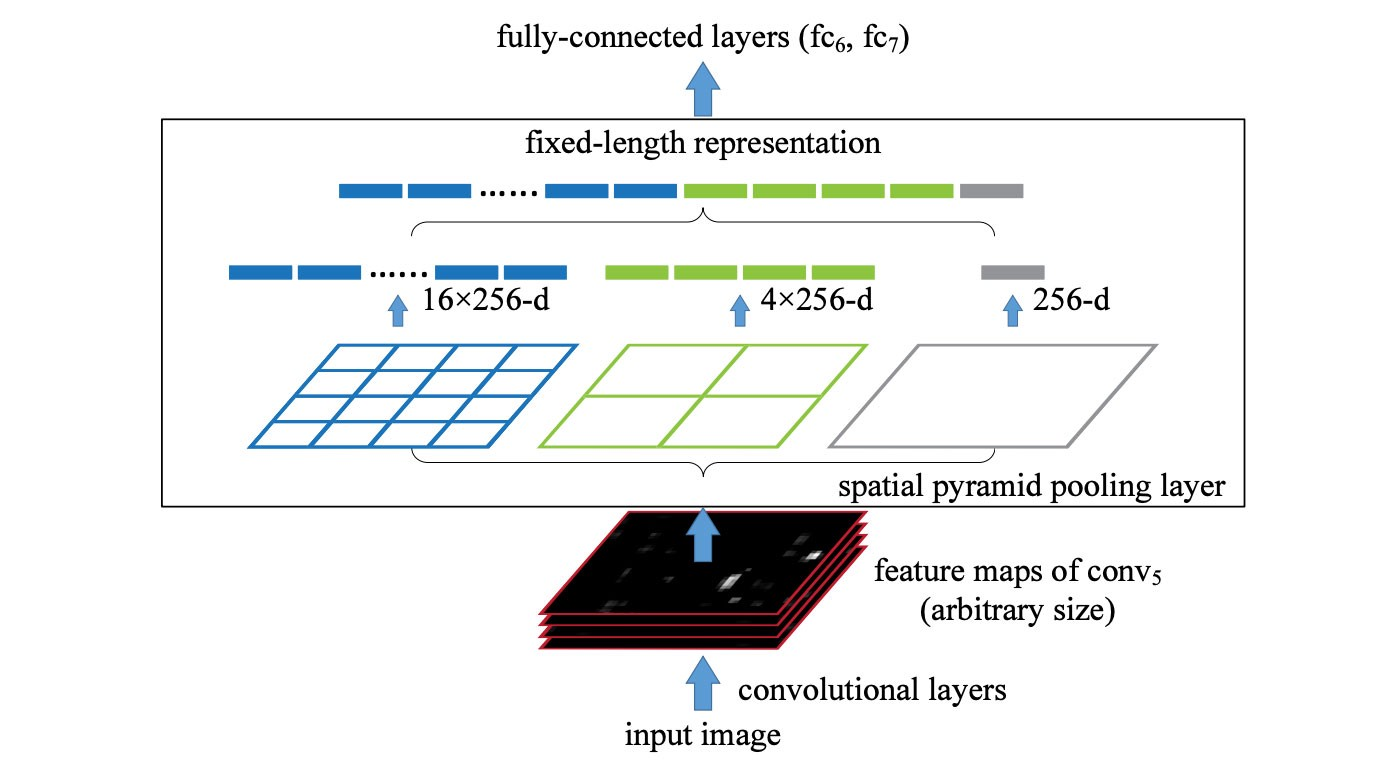
SPP (spatial pyramid pooling layer) SPP applies a slightly different strategy in detecting objects of different scales. It replaces the last pooling layer (after the last convolutional layer) with a spatial pyramid pooling layer. The feature maps are spatially divided into m×m bins with m, say, equals 1, 2, and 4 respectively. Then a maximum pool i...
Computer Vision
2026-01-11

原理分析 网络架构: 本文的任务是Object detection,用到的工具是Transformers,特点是Endtoend。 目标检测的任务是要去预测一系列的Bounding Box的坐标以及Label, 现代大多数检测器通过定义一些proposal,anchor或者windows,把问题构建成为一个分类和回归问题来间接地完成这个任务。文章所做的工作,就是将transformers运用到了object detection领域,取代了现在的模型需要手工设计的工作,并且取得了不错的结果。在object detection上DETR准确率和运行时间上和Faster RCNN相当;将模型 generalize 到 panoptic segmentation 任务上,DETR表现甚至还超过了其他...
Large Model
2026-01-11

UITARS 简介 UITARS(User Interface Task Automation and Reasoning System)是由字节跳动(ByteDance)研发的原生 GUI 智能体模型: 输入方式:仅使用屏幕截图作为视觉输入 交互方式:执行类人操作(键盘输入、鼠标点击、拖拽等) 模型特性:端到端的原生智能体模型,无需复杂的中间件或框架 传统 GUI 智能体的开发往往依赖于文本信息,例如 HTML 结构和可访问性树。虽然这些方法取得了一些进展,但它们也存在一些局限性: 平台不一致性:不同平台的 GUI 结构差异很大,导致智能体难以跨平台通用。 信息冗余:文本信息往往过于冗长,增加了模型的处理负担。 访问限制:获取系统底层的文本信息通常需要较高的权限,限制了应用的范围。 模块化...
Computer Vision
2026-01-11

一、IOU(Intersection over Union) 1. 特性(优点) IoU就是我们所说的交并比,是目标检测中最常用的指标,在anchorbased的方法中,他的作用不仅用来确定正样本和负样本,还可以用来评价输出框(predict box)和groundtruth的距离。 1. 可以说它可以反映预测检测框与真实检测框的检测效果。 1. 还有一个很好的特性就是尺度不变性,也就是对尺度不敏感(scale invariant), 在regression任务中,判断predict box和gt的距离最直接的指标就是IoU。(满足非负性;同一性;对称性;三角不等性) [代码] 2. 作为损失函数会出现的问题(缺点) 1. 如果两个框没有相交,根据定义,IoU=0,不能反映两者的距离大小(重...
Computer Vision
2026-01-11

Introduction 目标检测中NMS需要依据候选检测目标的排序来进行筛选框,如果分类得分较低,但是定位框准确会导致在NMS中将该bbox框被排除掉,因此这个排序的可靠性就非常重要。之前的工作主要采用IOU分支(IOUNet)与Centerness得分(FCOS)来作为大量候选检测的排序依据。 然而,本文认为这些方法可以有效缓解分类得分和物体定位精度之间的不对齐问题。 但是,它们是次优解的,因为将两个不完善的预测相乘可能会导致排名依旧变差,作者经过试验表明,通过这种方法实现的性能上限非常有限。 此外,增加一个额外的网络分支来预测定位分数并不是一个很好的解决方案,并且会带来额外的计算负担。 基于上述分析,作者提出:不采用预测一个额外的定位精确度得分(IOUaware Centerness)...
Computer Vision
2026-01-11
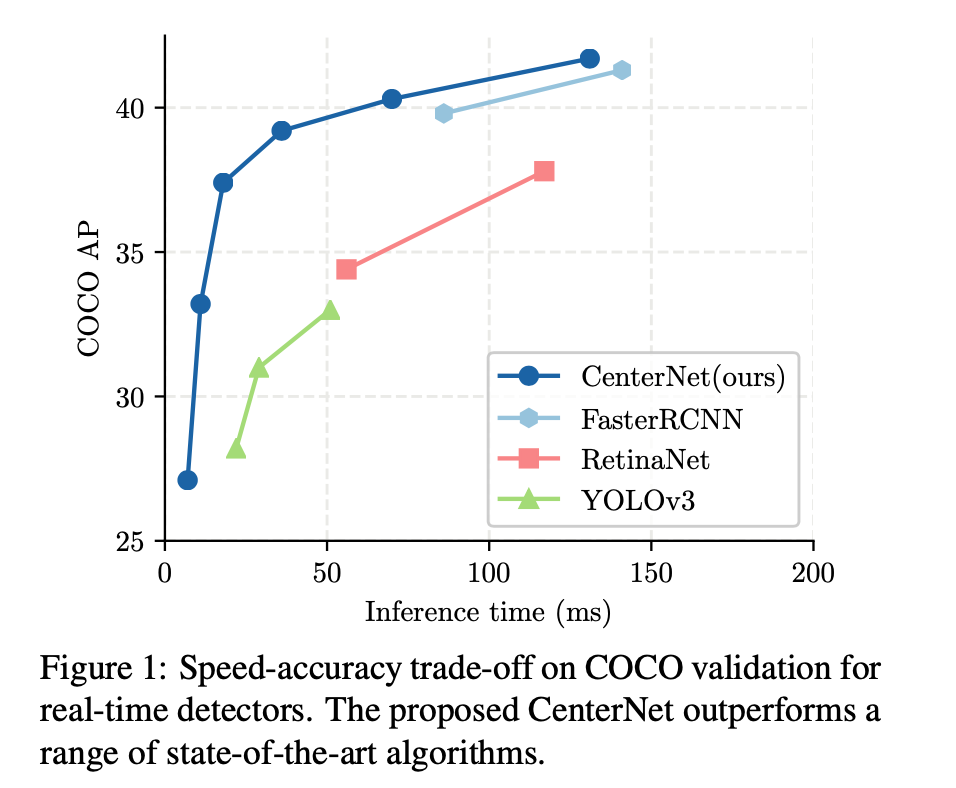
前言 anchorfree目标检测属于anchorfree系列的目标检测,相比于CornerNet做出了改进,使得检测速度和精度相比于onestage和twostage的框架都有不小的提高,尤其是与YOLOv3作比较,在相同速度的条件下,CenterNet的精度比YOLOv3提高了4个左右的点。 CenterNet不仅可以用于目标检测,还可以用于其他的一些任务,如肢体识别或者3D目标检测等等。 那CenterNet相比于之前的onestage和twostage的目标检测有什么特点? CenterNet的“anchor”仅仅会出现在当前目标的位置处而不是整张图上撒,所以也没有所谓的box overlap大于多少多少的算positive anchor这一说,也不需要区分这个anchor是物体还是...