
Apache Hadoop 是一款支持数据密集型分布式应用程序并以Apache 2.0许可协议发布的开源软件框架。它支持在商用硬件构建的大型集群上运行的应用程序。Hadoop是根据谷歌公司发表的MapReduce 和Google文件系统的论文自行实现而成。所有的Hadoop模块都有一个基本假设,即硬件故障是常见情况,应该由框架自动处理。具体参考 官方教程 。 Hadoop架构 HDFS: 分布式文件存储 YARN: 分布式资源管理 MapReduce: 分布式计算 Others: 利用YARN的资源管理功能实现其他的数据处理方式 内部各个节点基本都是采用Master-Woker架构 Hadoop HDFS 架构 Block数据块; 基本存储单位,一般大小为64M(配置大的块主要是因为:1)减少搜寻时间,一般硬盘传输速率比寻道时间要快,大的块可以减少寻道时间;2)减少管理块的数据开销,每个块都需要在NameNode上有对应的记录;3)对数据块进行读写,减少建立网络的连接成本)...
杂七杂八
2026-03-27

Quick Start 一个最简单的DDP Pytorch例子! 环境准备 PyTorch(gpu)>=1.5,python>=3.6 推荐使用官方打好的PyTorch docker,避免乱七八糟的环境问题影响心情。 # Dockerfile# Start FROM Nvidia PyTorch image https://ngc.nvidia.com/catalog/containers/nvidia:pytorch
# FROM nvcr.io/nvidia/pytorch:20.03-py3 代码 单GPU代码 ## main.py文件
import torch
# 构造模型
model = nn.Linear(10, 10).to(local_rank)
# 前向传播
outputs = model(torch.randn(20, 10).to(rank))
labels = torch.randn(20, 10).to(rank)
loss_fn = nn.MSELoss()
loss_fn(outputs, labels).backward()
#...
NLP
2026-03-26

这篇文章主要去“复盘”一下主流的长度外推结果,并试图从中发现免训练长度外推的关键之处。 问题定义 顾名思义,免训练长度外推,就是不需要用长序列数据进行额外的训练,只用短序列语料对模型进行训练,就可以得到一个能够处理和预测长序列的模型,即“Train Short, Test Long”。那么如何判断一个模型能否用于长序列呢?最基本的指标就是模型的长序列Loss或者PPL不会爆炸,更加符合实践的评测则是输入足够长的Context,让模型去预测答案,然后跟真实答案做对比,算BLEU、ROUGE等, LongBench 就是就属于这类榜单。 但要注意的是,长度外推应当不以牺牲远程依赖为代价——否则考虑长度外推就没有意义了,倒不如直接截断文本——这意味着通过显式地截断远程依赖的方案都需要谨慎选择,比如ALIBI,还有带显式Decay的 线性RNN ,这些方案当序列长度足够大时都表现为局部注意力,即便有可能实现长度外推,也会有远程依赖不足的风险,需要根据自己的场景斟酌使用。 如何判断在长度外推的同时有没有损失远程依赖呢?比较严谨的是像 ReRoPE...
Large Model
2026-03-18
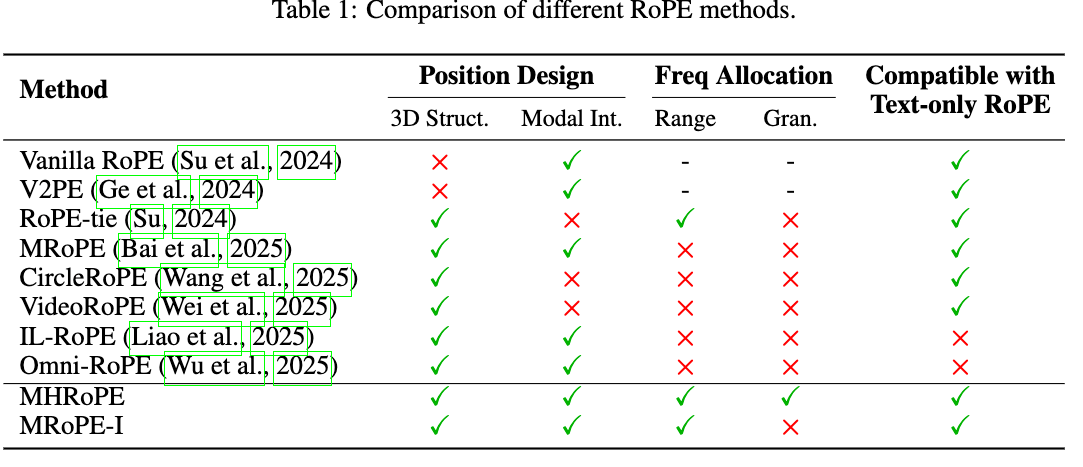
简介 论文: 《REVISITING MULTIMODAL POSITIONAL ENCODING IN VISION–LANGUAGE MODELS》 通过对多模态旋转位置嵌入(RoPE)的两个核心组件——位置设计和频率分配进行综合分析。通过实验,确定了三个关键指南:位置一致性、频率全利用和保留文本先验。基于这些见解,提出了多头RoPE(MHRoPE)和MRoPE-Interleave(MRoPE-I),这两种简单且即插即用的变体不需要任何架构更改。 为了构建更稳健的多模态位置编码,作者在MRoPE的基础上,系统地探索了三个未充分研究的方案: 位置设计——如何为文本和视觉标记分配无歧义、分离良好的坐标; 频率分配——如何将旋转频率分配到每个位置轴的嵌入维度; 与纯文本RoPE的兼容性——确保设计默认为标准RoPE,以便进行有效的迁移学习。 Vanilla RoPE RoPE与加性位置嵌入不同,RoPE对query和key向量应用旋转变换,从而将相对位置依赖直接纳入自注意力机制。给定位置 \(m\) 的查询向量 \(q\) 和位置 \(n\) 的键向量 \(k\) ,注意力分数...
NLP
2026-03-16
不同于RNN、CNN等模型,对于Transformer模型来说,位置编码的加入是必不可少的,因为纯粹的Attention模块是无法捕捉输入顺序的,即无法区分不同位置的Token。为此我们大体有两个选择: 想办法将位置信息融入到输入中,这构成了绝对位置编码的一般做法; 想办法微调一下Attention结构,使得它有能力分辨不同位置的Token,这构成了相对位置编码的一般做法。 虽然说起来主要就是绝对位置编码和相对位置编码两大类,但每一类其实又能衍生出各种各样的变种,为此研究人员可算是煞费苦心、绞尽脑汁了,此外还有一些不按套路出牌的位置编码。本文就让我们来欣赏一下研究人员为了更好地表达位置信息所构建出来的“八仙过海,各显神通”般的编码方案。 绝对位置编码 形式上来看,绝对位置编码是相对简单的一种方案,但即便如此,也不妨碍各路研究人员的奇思妙想,也有不少的变种。一般来说,绝对位置编码会加到输入中:在输入的第 𝑘 个向量 \(𝑥_𝑘\) 中加入位置向量 \(𝑝_𝑘\) 变为 \(\boldsymbol{x}_k + \boldsymbol{p}_k\) ,其中 \(...
Large Model
2026-03-12

概述 MTP(Multi-token Prediction)的总体思路是:让模型使用n个独立的输出头来预测接下来的n个token,这n个独立的输出头共享同一个模型主干。这样通过解码阶段的优化,将1-token的生成,转变成multi-token的生成,从而提升训练和推理的性能。 在DeepSeek之前也有几个MTP方案,其侧重点各自不同。 侧重推理时解码加速。比如论文“MEDUSA: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads”、论文“EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty”等。这些方案通过一次生成多个token,实现成倍的加速来提升推理性能。 侧重训练时提高效率。比如论文“Better & Faster Large Language Models via Multi-token...
Large Model
2026-03-12

概述 https://github.com/FasterDecoding/Medusa Medusa 是自投机领域较早的一篇工作,对后续工作启发很大,其主要思想是 multi-decoding head + tree attention + typical acceptance(threshold)。Medusa 没有使用独立的草稿模型,而是在原始模型的基础上增加多个解码头(MEDUSA heads),并行预测多个后续 token。 正常的LLM只有一个用于预测 \(t\) 时刻token的head。Medusa 在 LLM 的最后一个 Transformer层之后保留原始的 LM Head,然后额外增加多个(假设是 \(k\) 个) 可训练的Medusa Head(解码头),分别负责预测 \(t+1,t+2,...,\) 和 \(t+k\) 时刻的不同位置的多个 Token。 Medusa 让每个头生成多个候选 token,而非像投机解码那样只生成一个候选。然后将所有的候选结果组装成多个候选序列,多个候选序列又构成一棵树。再通过树注意力机制并行验证这些候选序列 。 原理...
Large Model
2026-03-10

概述 投机解码(Speculative Decoding)也叫预测解码/投机采样,它会利用小模型来预测大型模型的行为,从而提升模型在解码(decoding)阶段的解码效率问题,加速大型模型的执行。其核心思路如下图所示,首先以低成本的方式(以小模型为主,也有多头,检索,Early Exit 等方式)快速生成多个候选 Token(串行序列、树、多头树等),然后通过一次并行验证阶段快速验证多个 Token的正确性,只要平均每个 Step 验证的 Token 数 > 1,就可以一次性生成多个token,进而减少总的 Decoding 步数,实现加速的目的。 下图左侧是自回归解码模型,右侧是投机解码机制。 从本质上来说,投机解码希望在推理阶段在不大幅度改变模型的情况下,通过更好利用冗余算力来并行"投机"地猜测出模型接下来要输出的token。作为对比,也有一种方案是通过路由的方式组合多个不同规模和性能的模型。路由方式在调用之前已经确定好需要调用哪个模型,直到调用结束。而投机解码在一个 Query 内会反复调用大小模型。 背景 我们都知道,生成式 LLM 大部分是 Decoder-only...
Large Model
2026-03-10

引言 Structured Generation with LLM,是指 让LLM按照预先定义的schema,输出符合schema的结构化结果 。 常见的应用场景有: 数据处理 。主要功能为a -> b,即从源文本中 抽取/生成 符合schema的结果,例如给定新闻,进行分类、抽取关键词、生成总结等; Agent 。主要功能是Tool Calling,即根据用户query,选择适当的tool和入参。 将 LLM 限制为始终生成符合特定模式的、有效的 JSON 或 YAML,是许多应用的关键功能。 Kor Kor ,一个 基于prompt的技术方案 ;Kor比较适合 数据处理 场景,且原理简单、易于理解,适合作为入门, 并且Kor适用于那些不支持function calling的比较旧的模型。 使用Kor进行structured generation的流程如下: 定义schema,包括结构、注释还有例子; Kor用特定的 prompt template ,将用户提供的schema和待处理的raw text,组装成prompt; 将prompt发送给LLM,借助其通用的In...
Large Model
2026-03-10

通常我们训练神经网络模型的时候默认使用的数据类型为单精度FP32。近年来,为了加快训练时间、减少网络训练时候所占用的内存,并且保存训练出来的模型精度持平的条件下,业界提出越来越多的混合精度训练的方法。 这里的混合精度训练是指在训练的过程中,同时使用单精度(FP32)和半精度(FP16) 。 浮点数据类型 浮点数据类型主要分为双精度(FP64)、单精度(FP32)、半精度(FP16)。在神经网络模型的训练过程中,一般默认采用单精度(FP32)浮点数据类型,来表示网络模型权重和其他参数。在了解混合精度训练之前,这里简单了解浮点数据类型。 根据IEEE二进制浮点数算术标准(IEEE 754)的定义,浮点数据类型分为双精度(FP64)、单精度(FP32)、半精度(FP16)三种,其中每一种都有三个不同的位来表示。 FP64表示采用8个字节共64位,来进行的编码存储的一种数据类型; FP32表示采用4个字节共32位来表示; FP16则是采用2字节共16位来表示。 如图所示: 从图中可以看出,与FP32相比,FP16的存储空间是FP32的一半,FP32则是FP16的一半。主要分为三个部分:...
Large Model
2026-03-09

背景:大模型 vs. GPU Memory 大模型最大的特点是模型参数多,训练时需要很大的GPU显存 。举个例子,帮助大家的理解:对于一个常见的7B规模参数的大模型(如LLaMA-2 7B),基于16-bit混合精度训练时,在仅考虑模型参数、梯度、优化器情况下,显存占用就有112GB,显然目前A100、H100这样主流的显卡单张是放不下的,更别提国内中小厂喜欢用的A6000/5000、甚至消费级显卡。 上面的例子中,参数占GPU 显存近 14GB(每个参数2字节)。再考虑到训练时 梯度的存储占14GB(每个参数对应一个梯度,也是2字节)、优化器Optimizer假设是用目前主流的AdamW则是84GB(每个参数对应一个参数的copy、一个momentum和一个variance,这三个都是float32),合计112GB。 这种情况,Torch中支持的大家熟悉的数据并行 DataParallel 是解决不了的。因为数据并行的前提是每个GPU可以host完整的模型。需要用到模型并行和流水线并行。下面对着三种方法做一个简单介绍。 三种模型训练的并行方案 数据并行(Data...
Large Model
2026-03-09

引言与背景 FlashAttention的关键创新在于使用类似于在线Softmax的思想来对自注意力计算进行分块(tiling),从而能够融合整个多头注意力层的计算,而无需访问GPU全局内存来存储中间的logits和注意力分数 在深度学习中,Transformer模型的自注意力机制是计算密集型操作。传统实现需要在GPU全局内存中存储大量中间结果,这导致: 内存瓶颈 :中间矩阵占用大量显存 I/O开销 :频繁的全局内存访问降低效率 扩展性限制 :难以处理超长序列 FlashAttention通过算法创新解决了这些问题。 Self-Atention 自注意力机制的计算可以总结为(为简化说明,忽略头数和批次维度,也省略注意力掩码和缩放因子 \(\frac{1}{\sqrt{D}}\) ): \[O = \text{softmax}(QK^T)V\] 其中: \(Q, K, V, O\) 都是形状为 \((L, D)\) 的二维矩阵 \(L\) 是序列长度 \(D\) 是每个头的维度(头维度) softmax应用于最后一个维度(列) 标准计算流程, 传统方法将自注意力计算分解为几个阶段:...