
160. 相交链表 题目 给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。 图示两个链表在节点 c1 开始相交 : 题目数据 保证 整个链式结构中不存在环。 注意 ,函数返回结果后,链表必须 保持其原始结构 。 自定义评测: 评测系统 的输入如下(你设计的程序 不适用 此输入): intersectVal - 相交的起始节点的值。如果不存在相交节点,这一值为 0 listA - 第一个链表 listB - 第二个链表 skipA - 在 listA 中(从头节点开始)跳到交叉节点的节点数 skipB - 在 listB 中(从头节点开始)跳到交叉节点的节点数 评测系统将根据这些输入创建链式数据结构,并将两个头节点 headA 和 headB 传递给你的程序。如果程序能够正确返回相交节点,那么你的解决方案将被 视作正确答案 。 示例 1: 输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,6,1,8,4,5], skipA = 2,...

48. 旋转图像 题目 给定一个 \(n × n\) 的二维矩阵 matrix 表示一个图像。请你将图像顺时针旋转 90 度。 你必须在 原地 旋转图像,这意味着你需要直接修改输入的二维矩阵。 请不要 使用另一个矩阵来旋转图像。 示例 1: 输入:matrix = [[1,2,3],[4,5,6],[7,8,9]]
输出:[[7,4,1],[8,5,2],[9,6,3]] 示例 2: 输入:matrix = [[5,1,9,11],[2,4,8,10],[13,3,6,7],[15,14,12,16]]
输出:[[15,13,2,5],[14,3,4,1],[12,6,8,9],[16,7,10,11]] 提示: n == matrix.length == matrix[i].length 1 <= n <= 20 -1000 <= matrix[i][j] <= 1000 题解 这是一个经典的矩阵操作问题。要在原地(In-place)将图像顺时针旋转 90 度,我们可以利用矩阵的几何性质。 最直观且易于实现的方法是将...
Deep Learning
2026-01-22

文章从连续情形出发开始介绍重参数,主要的例子是正态分布的重参数;然后引入离散分布的重参数,这就涉及到了Gumbel Softmax,包括Gumbel Softmax的一些证明和讨论;最后再讲讲重参数背后的一些故事,这主要跟梯度估计有关。 基本概念 重参数(Reparameterization) 实际上是处理如下期望形式的目标函数的一种技巧: \[L_{\theta}=\mathbb{E}_{z\sim p_{\theta}(z)}[f(z)]\tag{1}\] 这样的目标在VAE中会出现,在文本GAN也会出现,在强化学习中也会出现( \(f(z)\) 对应于奖励函数),所以深究下去,我们会经常碰到这样的目标函数。取决于 \(z\) 的连续性,它对应不同的形式: \[\int p_{\theta}(z) f(z)dz\,\,\,\text{(连续情形)}\qquad\qquad \sum_{z} p_{\theta}(z) f(z)\,\,\,\text{(离散情形)}\tag{2}\] 当然,离散情况下我们更喜欢将记号 \(z\) 换成 \(y\) 或者 \(c\) 。 为了最小化...
数组&链表&字符串 双指针 滑动窗口 哈希表 哈希表 栈&队列 单调队列 树与堆 图 数学 Math
Generative Model
2026-01-19
基于文章 《Elucidating the Design Space of Diffusion-Based Generative Models》 来统一扩散模型框架 通用扩散模型框架推导 加噪公式 Flow Matching的一步加噪公式 \[\mathbf{x}_t=(1-t)\mathbf{x}_0+t\varepsilon\] 写成概率分布形式: \[p(\mathbf{x}_t|\mathbf{x}_0)=\mathcal{N}(\mathbf{x}_t;(1-t)\mathbf{x}_0,t^2\mathbf{I})\] Score Matching的一步加噪公式 \[\mathbf{x}_t=\mathbf{x}_0+\sigma_t\varepsilon \] 写成概率分布形式: \[p(\mathbf{x}_t|\mathbf{x}_0)=\mathcal{N}(\mathbf{x}_t;\mathbf{x}_0,\sigma_t^2\mathbf{I})\] DDPM/DDIM的一步加噪公式...
Generative Model
2026-01-18
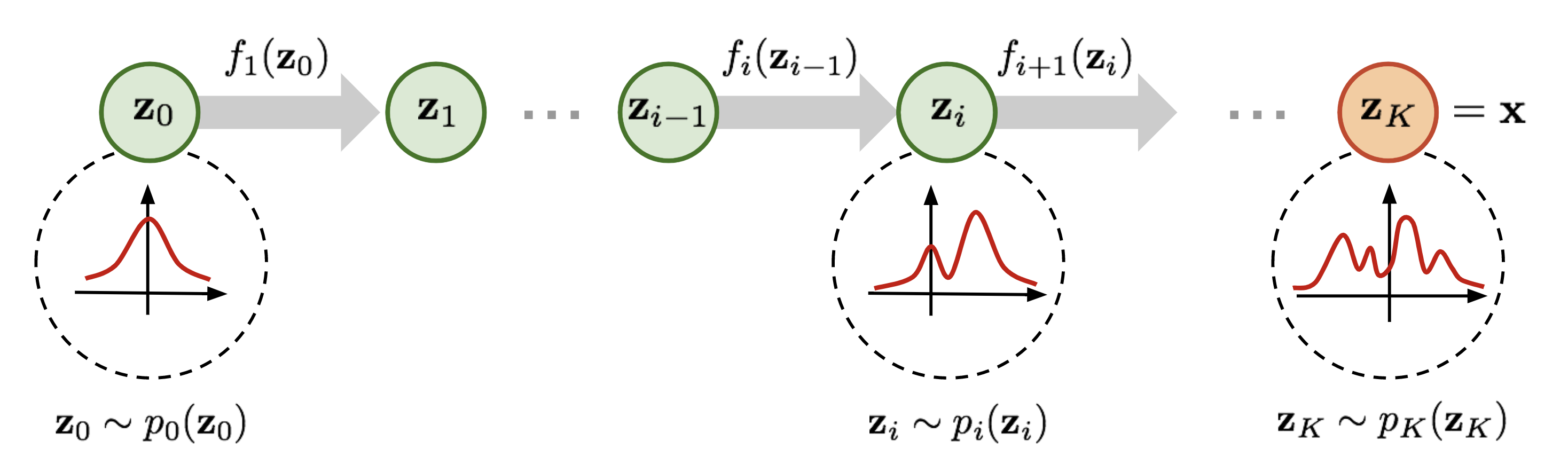
Normalizing flow(标准化流)是一类对概率分布进行建模的工具,它能完成简单的概率分布(例如高斯分布)和任意复杂分布之间的相互转换,经常被用于 data generation、density estimation、inpainting 等任务中,例如 Stability AI 提出的 Stable Diffusion 3 中用到的 rectified flow 就是 normalizing flow 的变体之一。 为了便于理解,在正式开始介绍之前先简要说明一下 normalizing flow 的做法。如上图所示,为了将一个高斯分布 \(z_0\) 转换为一个复杂的分布 \(z_K\) ,normalizing flow 会对初始的分布 \(z_0\) 进行多次可逆的变换,将其逐渐转换为 \(z_K\) 。由于每一次变换都是可逆的,从 \(z_K\) 出发也能得到高斯分布 \(z_0\) 。这样,我们就实现了复杂分布与高斯分布之间的互相转换,从而能从简单的高斯分布建立任意复杂分布。 对 diffusion models 比较熟悉的读者可能已经发现了,这个过程和...
Deep Learning
2026-01-11
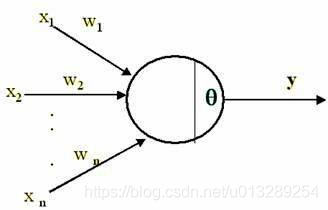
1.深度学习偏置的作用? 我们在学深度学习的时候,最早接触到的神经网络应该属于感知器(感知器本身就是一个很简单的神经网络,也许有人认为它不属于神经网络,当然认为它和神经网络长得像也行) 要想激活这个感知器,使得 y=1 ,就必须使 x_1w_1 + x_2w_2 +....+x_nw_n T ( T 为一个阈值),而 T 越大,想激活这个感知器的难度越大,人工选择一个阈值并不是一个好的方法,因为样本那么多,我不可能手动选择一个阈值,使得模型整体表现最佳,那么我们可以使得T变成可学习的,这样一来, T 会自动学习到一个数,使得模型的整体表现最佳。当把T移动到左边,它就成了偏置, x_1w_1 + x_2w_2 +....+x_nw_n T 0 xw +b 0 ,总之,偏置的大小控制着激活这个感...
Deep Learning
2026-01-11
一般来说,神经网络处理的东西都是连续的浮点数,标准的输出也是连续型的数字。但实际问题中,我们很多时候都需要一个离散的结果,比如分类问题中我们希望输出正确的类别,“类别”是离散的,“类别的概率”才是连续的;又比如我们很多任务的评测指标实际上都是离散的,比如分类问题的正确率和F1、机器翻译中的BLEU,等等。 还是以分类问题为例,常见的评测指标是正确率,而常见的损失函数是交叉熵。交叉熵的降低与正确率的提升确实会有一定的关联,但它们不是绝对的单调相关关系。换句话说,交叉熵下降了,正确率不一定上升。显然,如果能用正确率的相反数做损失函数,那是最理想的,但正确率是不可导的(涉及到 [Math] 等操作),所以没法直接用。 这时候一般有两种解决方案;一是动用强化学习,将正确率设为奖励函数,这是“用牛刀杀...

简介 生成树(spanning tree) 在图论中,无向图 G=(V,E) 的生成树(spanning tree)是具有G的全部顶点,但边数最少的联通子图。假设G中一共有n个顶点,一颗生成树满足下列条件: (1)n个顶点; (2)n1条边; (3)n个顶点联通; (4)一个图的生成树可能有多个。最小生成树(minimum spanning tree, MST)/最小生成森林:联通加权无向图中边缘权重加和最小的生成树。给定无向图 G=(V,E) , (u,v) 代表顶点 u 与顶点 v 的边, w(u,v) 代表此边的权重,若存在生成树T使得: [公式] 最小,则 T 为 G 的最小生成树。对于非连通无向图来说,它的每一连通分量同样有最小生成树,它们的并被称为最小生成森林。最小生成树除了继承...
Deep Learning
2026-01-11
如何计算RF 公式一:这个算法从top往下层层迭代直到追溯回input image,从而计算出RF。 [公式] 其中,RF是感受野。RF和RF有点像,N代表 neighbour,指的是第n层的 a feature在n1层的RF,记住N_RF只是一个中间变量,不要和RF混淆。 stride是步长,ksize是卷积核大小。
Algorithm
2026-01-11
给一个无向图,判断其是否为一棵树。如果是树的话,所有的节点必须是连接的,也就是说必须是连通图,而且不能有环,所以就变成了验证是否是连通图和是否含有环。 [代码]