Machine Learning
2026-01-11
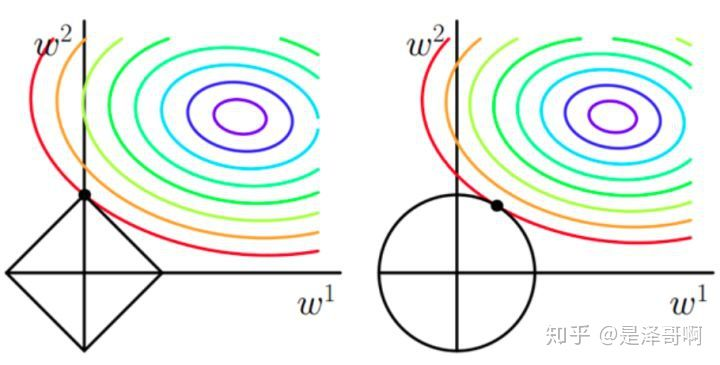
正则化 正则化是一个通用的算法和思想,所以会产生过拟合现象的算法都可以使用正则化来避免过拟合。 在经验风险最小化的基础上(也就是训练误差最小化),尽可能采用简单的模型,可以有效提高泛化预测精度。如果模型过于复杂,变量值稍微有点变动,就会引起预测精度问题。正则化之所以有效,就是因为其降低了特征的权重,使得模型更为简单。 正则化一般会采用 L1 范式或者 L2 范式,其形式分别为 [Math] 和 [Math] 。 L1正则化 LASSO 回归,相当于为模型添加了这样一个先验知识: w 服从零均值拉普拉斯分布。 首先看看拉普拉斯分布长什么样子: [公式] 由于引入了先验知识,所以似然函数这样写: [公式] 取 log 再取负,得到目标函数: [公式] 等价于原始损失函数的后面加上了 L1 正则,...