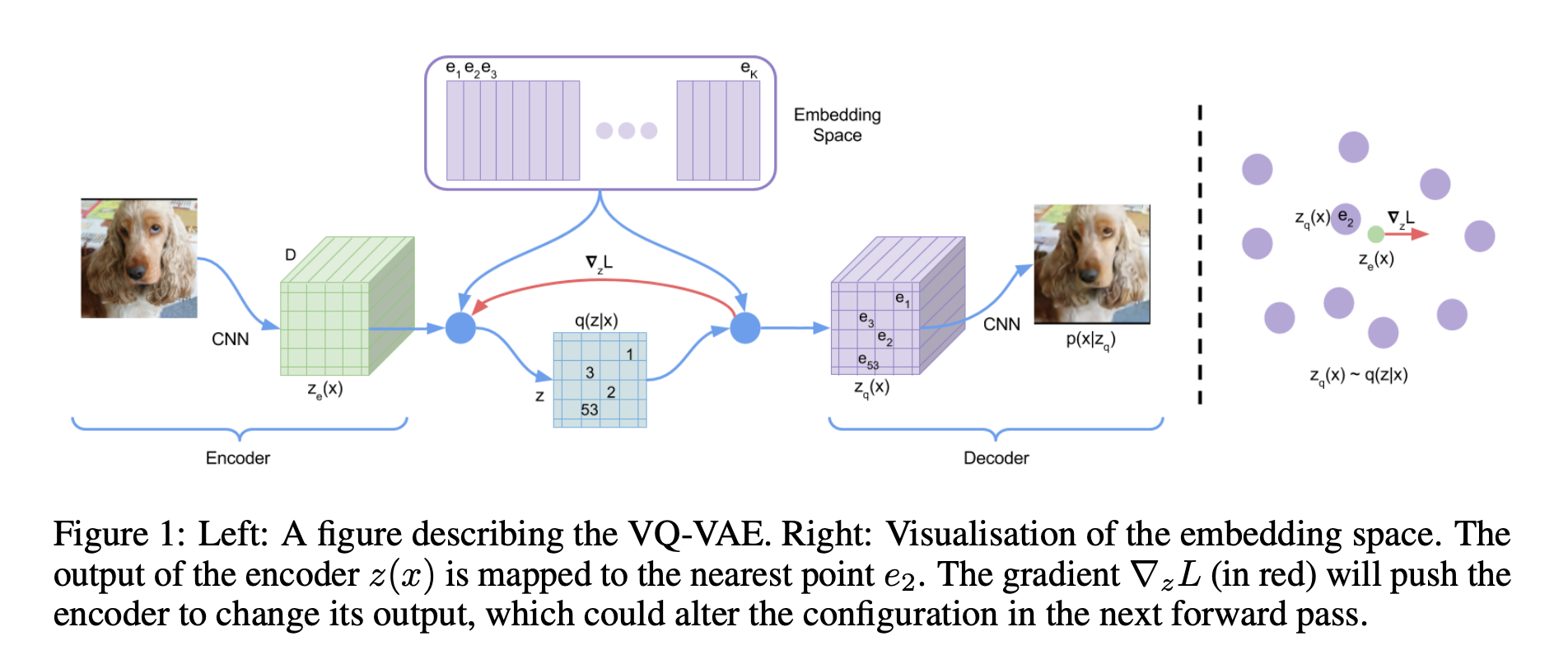
Generative Model
2026-04-02

研究对象与基本设定 我们希望学习一个能够“生成数据”的概率模型。假设我们有一个数据集 \(D\) ,每个样本是 \(n\) 维二值向量: \(x \in \{0,1\}^n\) 我们的目标是用一个参数化分布 \(p_\theta(x)\) 去逼近真实数据分布 \(p_{\text{data}}(x)\) ,并最终能够: 密度估计 :给定 \(x\) 计算 \(p_\theta(x)\) 或 \(\log p_\theta(x)\) 采样生成 :从 \(p_\theta(x)\) 采样得到新的 \(x\) 给定一个具体的任务,如MNIST中的手写数字二值图分类, 从Generative的角度进行Represent,并在Inference中Learning. 下面先介绍: 描述如何对这个MINST任务建模 \(p(X,Y)\) (Representation) 对MNIST任务建模 对于一张pixel为 \(28\times28\) 大小的图片,令 \(x_1\) 表示第一个pixel的随机变量, \(x_1\in\{0,1\}\) ,需明确: 任务目标:学习一个模型分布...