Large Model
2026-01-26
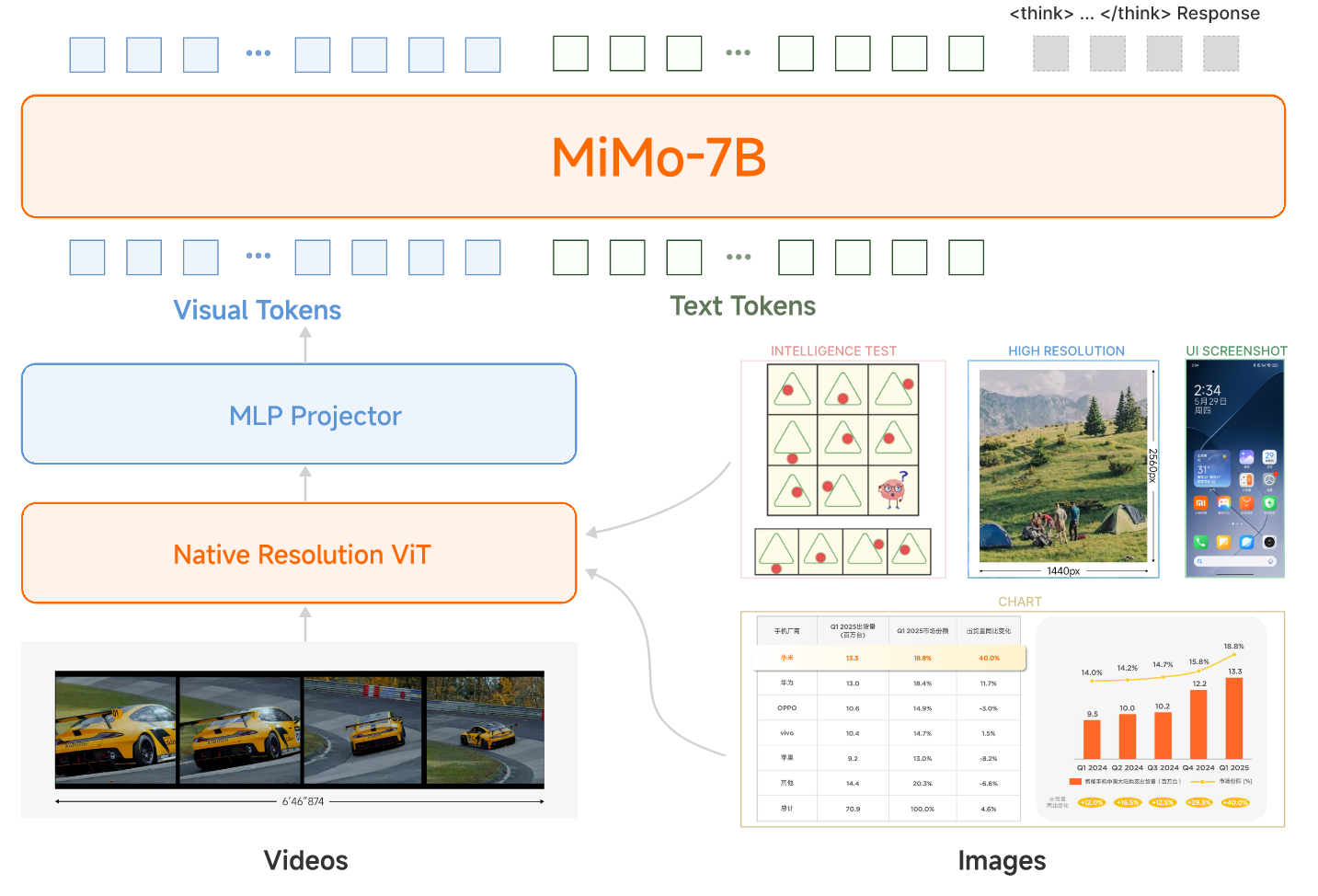
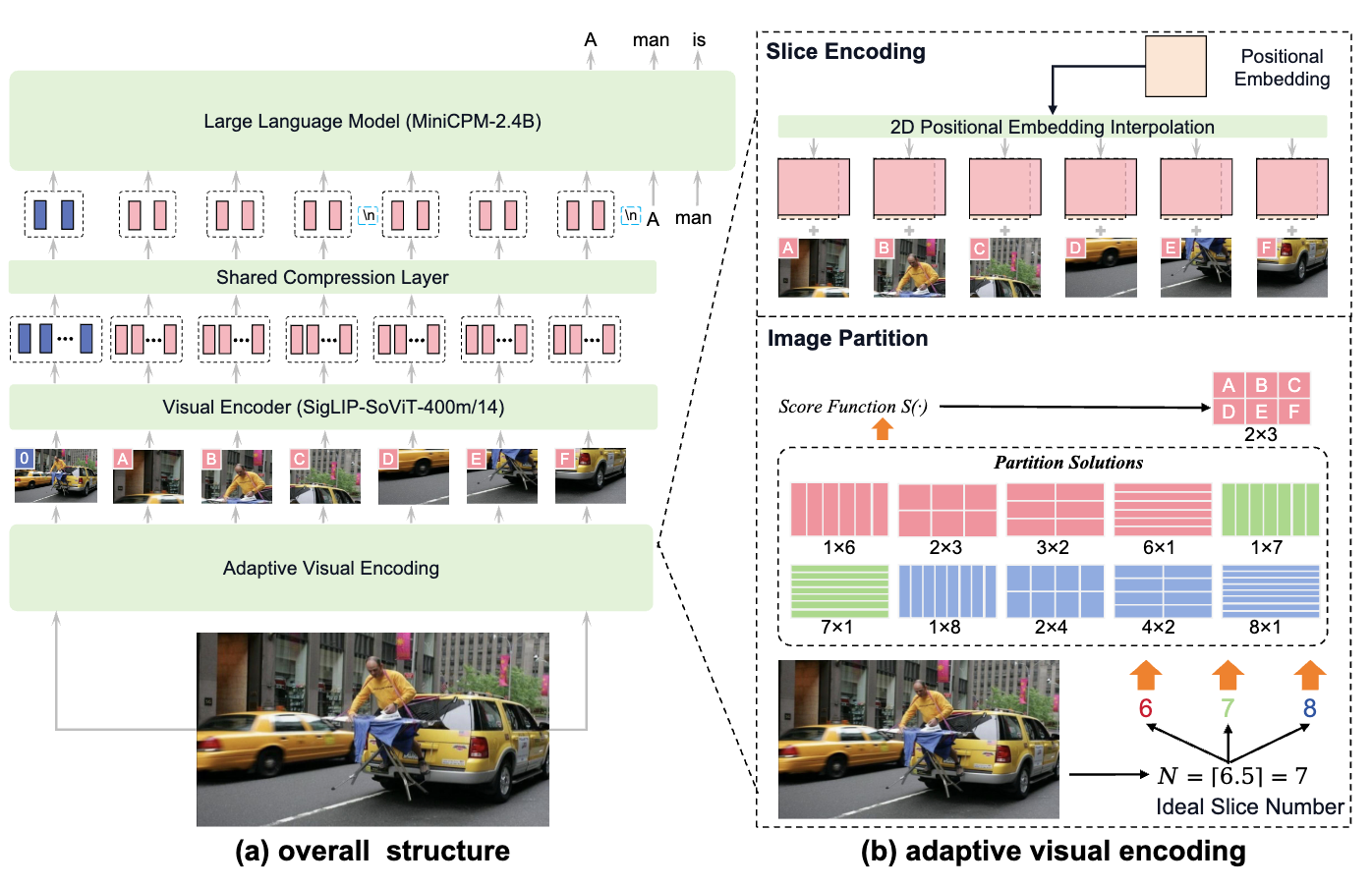
概述 小米团队近日发布了MIMO-VL-7B-SFT和MIMO-VL-7B-RL,这是两个强大的视觉语言模型,MIMO-VL-7B-RL在40个评估任务中的35个上优于QWEN2.5-VL-7B,对于GUI Grounding任务,它在OSWorld-G上设置了一个新标准,甚至超过了UI-TARS等专业模型。模型通过四个阶段的预训练(2.4T Token)与Mixed On-policy 强化(MORL)整合了多样化的奖励信号。 在文章中,作者提到了两个重要的发现: 从Pre-Traing 训练阶段中加入高质量且覆盖广的推理数据对于强化模型性能至关重要。 Mixed On-policy 强化学习进一步增强了模型的性能,同时实现了稳定的同时改进仍然在性能方面具有挑战性。 Pre-Training 模型结构 整个模型还是采用了VIT-MLP-LLM的结构,具体来说,视觉模型采用了Qwen2.5-VL中的视觉encoder,LLM采用了自家的语言模型MiMo-7B-Base。 整个Pretraining采用了四个阶段的训练,每个阶段采用的数据,模型训练参数和模型参数如下面两表所示...