
💡 GRPO相比PPO主要优势: 1. 训练更稳定 引入 KL 散度惩罚项,有效控制策略更新的幅度,避免策略崩溃,提高训练的稳定性 GRPO用组内相对优势替代value model,消除了value估计误差 通过组内归一化,自动消除reward scale和bias的影响 实验中发现GRPO的advantage方差比PPO小30%左右,训练崩溃率更低 2. 工程更简单 只需要1-2个模型(policy + reference),而PPO需要4个 显存占用减少50%以上,训练速度提升2-3倍 超参数更少,更容易调优 3. 相对奖励机制 通过对同一输入生成的多个输出进行比较,GRPO 能够更稳定地估计优势函数,减少了训练过程中的方差 背景 GRPO是 DeepSeek-Math model中提出的对PPO方法的改进策略: 强化学习(RL)在提升模型数学推理能力方面被证明是有效的 传统PPO算法需要较大训练资源 GRPO作为PPO的变体被提出,可以更高效地优化模型 PPO Vs GRPO PPO回顾 PPO的目标函数为: \[\begin{aligned}J_{PPO}(\theta) =...
NLP
2026-03-26

概述 众所周知,尽管基于Attention机制的Transformer类模型有着良好的并行性能,但它的空间和时间复杂度都是 \(\mathcal{O}(n^2)\) 级别的, \(n\) 是序列长度,所以当 \(n\) 比较大时Transformer模型的计算量难以承受。近来,也有不少工作致力于降低Transformer模型的计算量,比如模型剪枝、量化、蒸馏等精简技术,又或者修改Attention结构,使得其复杂度能降低到 \(\mathcal{O}(n\log n)\) 甚至 \(\mathcal{O}(n)\) 。 改变这一复杂度的思路主要有两种: 一是走稀疏化的思路,比如OpenAI的 Sparse Attention ,通过“只保留小区域内的数值、强制让大部分注意力为零”的方式,来减少Attention的计算量。经过特殊设计之后,Attention矩阵的大部分元素都是0,因此理论上它也能节省显存占用量和计算量。后续类似工作还有 《Explicit Sparse Transformer: Concentrated Attention Through Explicit...
NLP
2026-03-26

Attention 当前最流行的Attention机制当属 Scaled-Dot Attention,形式为 \[\begin{equation}Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}) = softmax\left(\boldsymbol{Q}\boldsymbol{K}^{\top}\right)\boldsymbol{V}\tag{1}\end{equation}\] 这里的 \(\boldsymbol{Q}\in\mathbb{R}^{n\times d_k}, \boldsymbol{K}\in\mathbb{R}^{m\times d_k}, \boldsymbol{V}\in\mathbb{R}^{m\times d_v}\) ,简单起见我们就没显式地写出Attention的缩放因子了。本文我们主要关心Self Attention场景,所以为了介绍上的方便统一设 \(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V}\in\mathbb{R}^{n\times...
Attention 当前最流行的Attention机制当属 Scaled-Dot Attention,形式为 \[\begin{equation}Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}) = softmax\left(\boldsymbol{Q}\boldsymbol{K}^{\top}\right)\boldsymbol{V}\tag{1}\end{equation}\] 这里的 \(\boldsymbol{Q}\in\mathbb{R}^{n\times d_k}, \boldsymbol{K}\in\mathbb{R}^{m\times d_k}, \boldsymbol{V}\in\mathbb{R}^{m\times d_v}\) ,简单起见我们就没显式地写出Attention的缩放因子了。本文我们主要关心Self Attention场景,所以为了介绍上的方便统一设 \(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V}\in\mathbb{R}^{n\times...
NLP
2026-03-26

概述 SSM的概念由来已久,但这里我们特指深度学习中的SSM,一般认为其开篇之作是2021年的 S4 ,不算太老,而SSM最新最火的变体大概是 Mamba 。当然,当我们谈到SSM时,也可能泛指一切线性RNN模型,这样 RWKV 、 RetNet 还有此前LRU都可以归入此类。不少SSM变体致力于成为Transformer的竞争者,尽管笔者并不认为有完全替代的可能性,但SSM本身优雅的数学性质也值得学习一番。 尽管我们说SSM起源于S4,但在S4之前,SSM有一篇非常强大的奠基之作 《HiPPO: Recurrent Memory with Optimal Polynomial Projections》 (简称HiPPO),所以本文从HiPPO开始说起。 另外值得一提的是,SSM代表作HiPPO、S4、Mamba的一作都是 Albert Gu ,他还有很多篇SSM相关的作品,毫不夸张地说,这些工作筑起了SSM大厦的基础。不论SSM前景如何,这种坚持不懈地钻研同一个课题的精神都值得我们由衷地敬佩。 今天,基本上你能叫出的任何语言模型都是 Transformer 模型。OpenAI 的...
NLP
2026-03-25

概述 本文模型脉络图 本文介绍一个比较有意思的高效Transformer工作——来自Google的 《Transformer Quality in Linear Time》 , 什么样的结果值得我们用“惊喜”来形容?有没有言过其实?我们不妨先来看看论文做到了什么: 提出了一种新的Transformer变体,它依然具有二次的复杂度,但是相比标准的Transformer,它有着更快的速度、更低的显存占用以及更好的效果; 提出一种新的线性化Transformer方案,它不但提升了原有线性Attention的效果,还保持了做Decoder的可能性,并且做Decoder时还能保持高效的训练并行性。 说实话,笔者觉得做到以上任意一点都是非常难得的,而这篇论文一下子做到了两点,所以我愿意用“惊喜满满”来形容它。更重要的是,论文的改进总的来说还是比较自然和优雅的,不像很多类似工作一样显得很生硬。此外,笔者自己也做了简单的复现实验,结果显示论文的可复现性应该是蛮好的,所以真的有种“Transformer危矣”的感觉了。 门控注意(Gated Attention Unit)...
NLP
2026-03-25

Attention 当前最流行的Attention机制当属 Scaled-Dot Attention,形式为 \[Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}) = softmax\left(\boldsymbol{Q}\boldsymbol{K}^{\top}\right)\boldsymbol{V}\tag{1}\] 这里的 \(\boldsymbol{Q}\in\mathbb{R}^{n\times d_k}, \boldsymbol{K}\in\mathbb{R}^{m\times d_k}, \boldsymbol{V}\in\mathbb{R}^{m\times d_v}\) ,简单起见我们就没显式地写出Attention的缩放因子了。本文我们主要关心Self Attention场景,所以为了介绍上的方便统一设 \(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V}\in\mathbb{R}^{n\times d}\) ,一般场景下都有 \(n > d\) 甚至...
Large Model
2026-03-10

k1.5—CoT强化训练 概述 Kimi k1.5采用了一种简化而有效的强化学习框架,其核心在于长上下文扩展和改进的策略优化方法,而不依赖于更复杂的技术如蒙特卡洛树搜索、价值函数和过程奖励模型。 问题设定 给定训练数据集 \(D = \{(x_i, y^*_i)\}_{i=1}^n\) ,其中包含问题 \(x_i\) 和对应的真实答案 \(y^*_i\) ,目标是训练一个策略模型 \(\pi_\theta\) 来准确解决测试问题。在复杂推理场景中,思维链(CoT)方法提出使用一系列中间步骤 \(z = (z_1, z_2, ..., z_m)\) 来连接问题 \(x\) 和答案 \(y\) ,每个 \(z_i\) 是解决问题的重要中间步骤。 当解决问题 \(x\) 时,思维 \(z_t \sim \pi_\theta(\cdot|x, z_1, ..., z_{t-1})\) 被自回归采样,最终答案 \(y \sim \pi_\theta(\cdot|x, z_1, ..., z_m)\) 。 强化学习目标 基于真实答案 \(y^*\) ,分配一个值 \(r(x, y, y^*)...
3D Model
2026-02-12
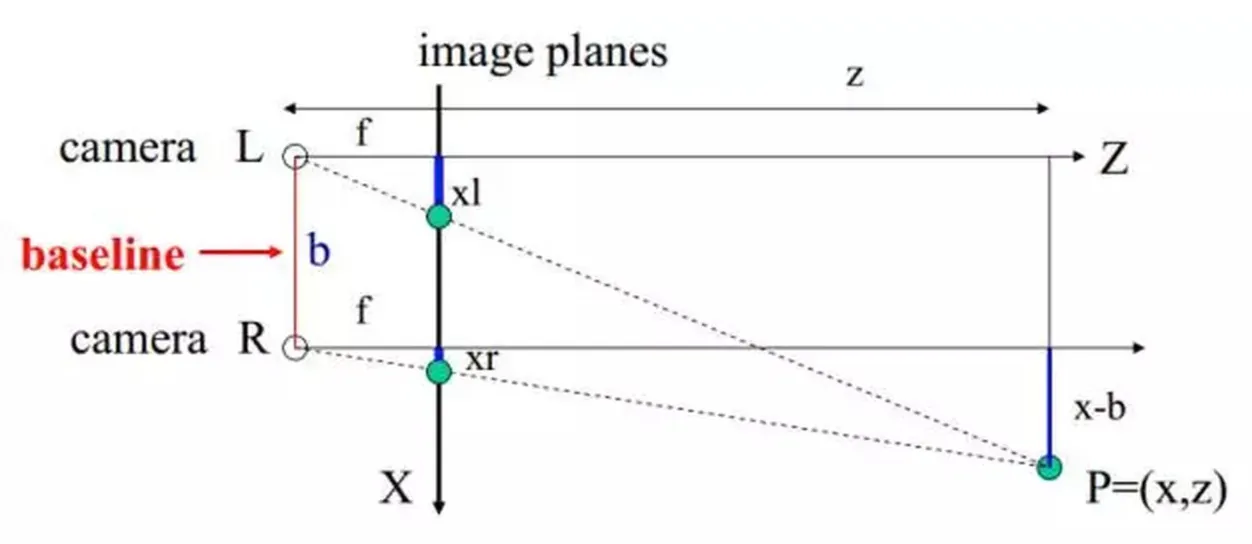
深度相机 “工欲善其事必先利其器‘’我们先从能够获取RGBD数据的相机开始谈起。首先我们来看一看其分类。 根据其工作原理主要分为三类: 1.双目方案 基于双目立体视觉的深度相机类似人类的双眼,和基于TOF、结构光原理的深度相机不同,它不对外主动投射光源,完全依靠拍摄的两张图片(彩色RGB或者灰度图)来计算深度,因此有时候也被称为被动双目深度相机。比较知名的产品有STEROLABS 推出的 ZED 2K Stereo Camera和Point Grey 公司推出的 BumbleBee。 双目立体视觉是基于视差原理,由多幅图像获取物体三维几何信息的方法。在机器视觉系统中, 双目视觉一般由双摄像机从不同角度同时获取周围景物的两幅数字图像,或有由单摄像机在不同时刻从不同角度获取周围景物的两幅数字图像 ,并基于视差原理即可恢复出物体三维几何信息,重建周围景物的三维形状与位置。 双目视觉有的时候我们也会把它称为体视,是人类利用双眼获取环境三维信息的主要途径。从目前来看,随着机器视觉理论的发展,双目立体视觉在机器视觉研究中发回来看了越来越重要的作用 为什么非得用双目相机才能得到深度?...
3D Model
2026-02-12
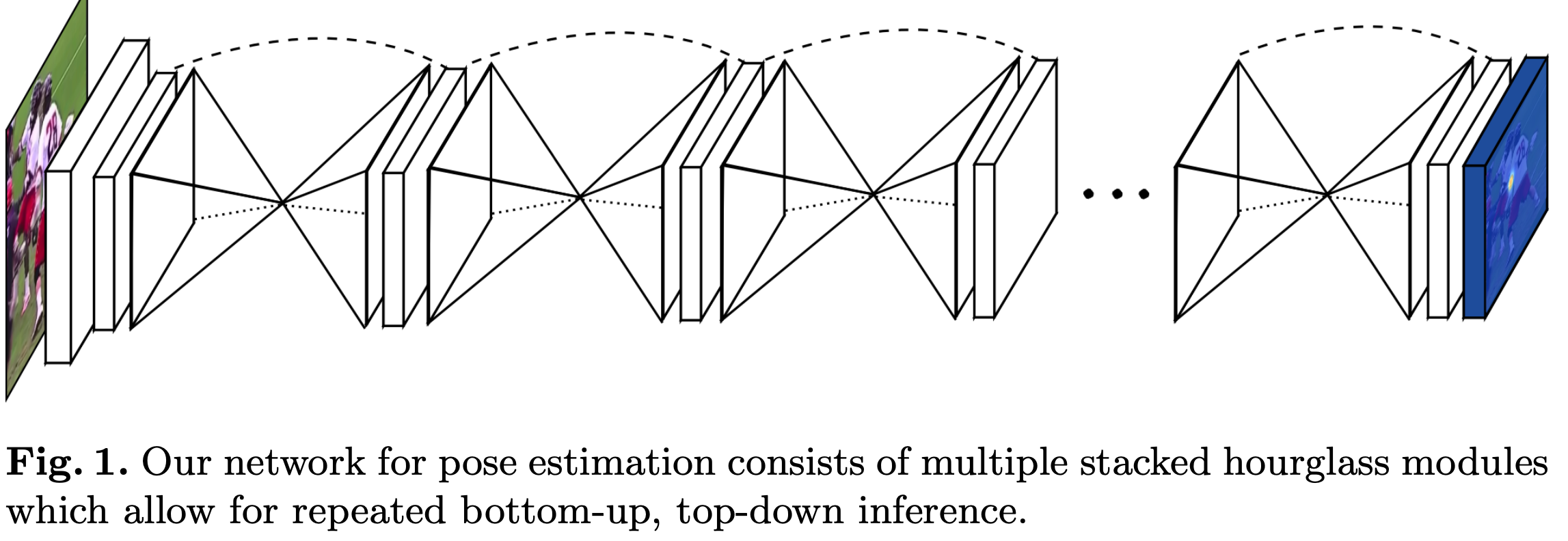
论文介绍了一种新的网络结构用于人体姿态检测,作者在论文中展现了不断重复bottom-up、top-down过程以及运用intermediate supervison(中间监督)对于网络性能的提升,下面来介绍Stacked Hourglass Networks. 简介 理解人类的姿态对于一些高级的任务比如行为识别来说特别重要,而且也是一些人机交互任务的基础。作者提出了一种新的网络结构Stacked Hourglass Networks来对人体的姿态进行识别,这个网络结构能够捕获并整合图像所有尺度的信息。之所以称这种网络为Stacked Hourglass Networks,主要是它长得很像堆叠起来的沙漏,如下图所示: 这种堆叠在一起的Hourglass模块结构是对称的,bottom-up过程将图片从高分辨率降到低分辨率,top-down过程将图片从低分辨率升到高分辨率,这种网络结构包含了许多pooling和upsampling的步骤,pooling可以将图片降到一个很低的分辨率,upsampling可以结合多个分辨率的特征。 下面介绍具体的网络结构。 Hourglass Module...
3D Model
2026-02-12
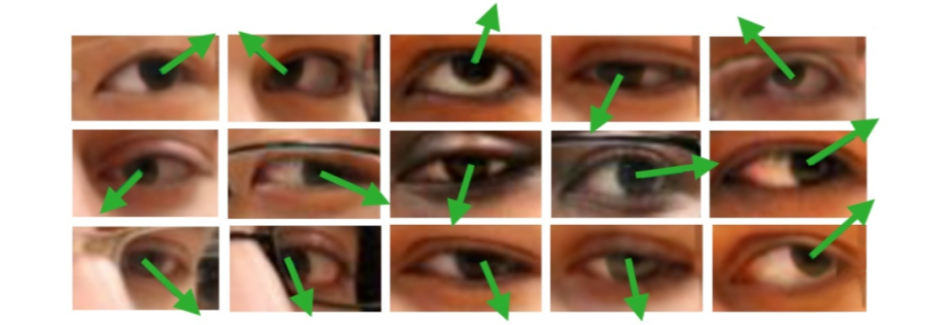
概述 问题定义 广义的 Gaze Estimation 泛指与眼球、眼动、视线等相关的研究,因此有不少做 saliency 和 egocentric 的论文也以 gaze 为关键词。而本文介绍的 Gaze Estimation 主要以眼睛图像或人脸图像为处理对象,估算人的视线方向或注视点位置, 如下图所示。 gaze角度的表示一般使用一个3d向量作为表示,也可以转换为pitch 和yaw角度,具体可参考 欧拉角、旋转矩阵、旋转向量、四元数 Model Gaze模型一般使用回归模型,所以这里基本只介绍一些在gaze model中使用的小技巧 Rle Loss RLE Loss 实际问题 Gaze采集标定方案
3D Model
2026-02-12
整体流程 # 文件夹biaoding处理加crop以及生成.yml系列文件,保存在calib_params以及biaoding_pipeline文件夹中
0_test_calibprocess.sh
# 内参标定,往往需要多天数据,且要保证标定板出现的多样性以及cover大部分区域
1_calib_intrics.sh
# 外参标定,使用混合的内参对单天数据进行外参标定,最好loss在0.000x
1_calib_extrics.sh
# 修改anchor.yaml相机信息进行15标定,loss 100以下,A88参考为50左右
2_test_merge.sh
# 选择数据送标anchor,返回后, loss 0.00x, 不准基本就是anchor标错或者方向盘等位置发生运动
python tools/display_tags.py --anchor_path /mnt/.../anchor
3_test_anchors.sh
# 检查anchor的3d位置是否正确
# 首先根据点位加入颜色
python 3_addcolor_anchor.py
#...