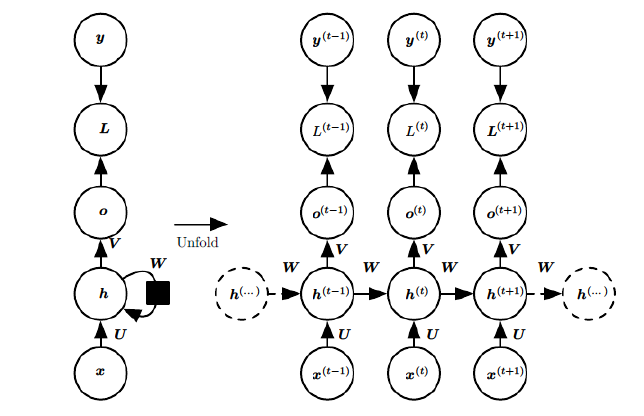
RNN 概述 在前面讲到的DNN和CNN中,训练样本的输入和输出是比较的确定的。但是有一类问题DNN和CNN不好解决,就是训练样本输入是连续的序列,且序列的长短不一,比如基于时间的序列:一段段连续的语音,一段段连续的手写文字。这些序列比较长,且长度不一,比较难直接的拆分成一个个独立的样本来通过DNN/CNN进行训练。 而对于这类问题,RNN则比较的擅长。那么RNN是怎么做到的呢?RNN假设我们的样本是基于序列的。比如是从序列索引1到序列索引 \(τ\) 。对于这其中的任意序列索引号 \(t\) ,它对应的输入是对应的样本序列中的 \(x(t)\) 。而模型在序列索引号 \(t\) 位置的隐藏状态 \(h(t)\) ,则由 \(x(t)\) 和在 \(t−1\) 位置的隐藏状态 \(h(t−1)\) 共同决定。在任意序列索引号 \(t\) ,我们也有对应的模型预测输出 \(o(t)\) 。通过预测输出 \(o(t)\) 和训练序列真实输出 \(y(t)\) ,以及损失函数 \(L(t)\) ,我们就可以用DNN类似的方法来训练模型,接着用来预测测试序列中的一些位置的输出。...
NLP
2026-03-23
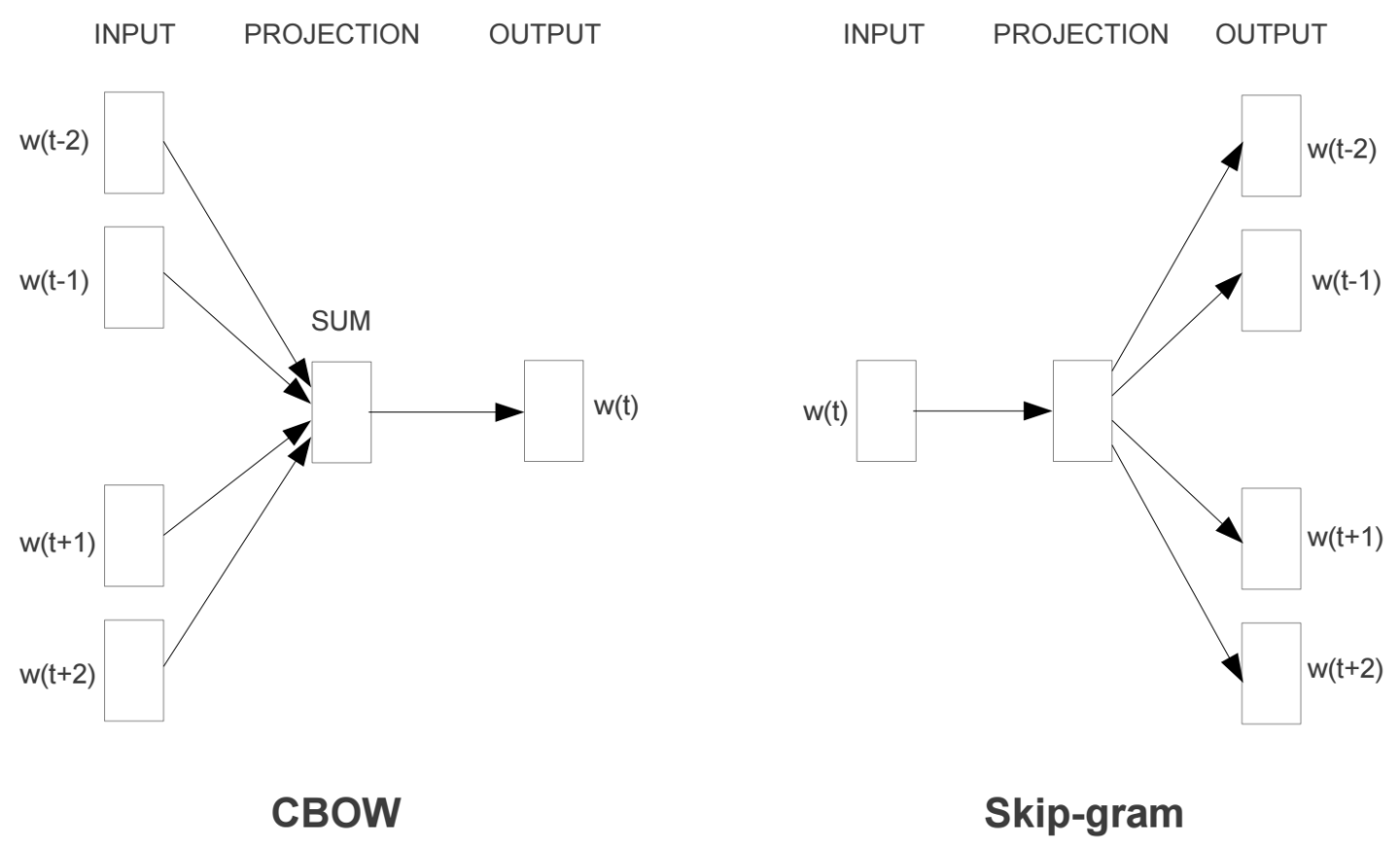
什么是Word2Vec和Embeddings? Word2Vec是从大量文本语料中以无监督的方式学习语义知识的一种模型,它被大量地用在自然语言处理(NLP)中。那么它是如何帮助我们做自然语言处理呢?Word2Vec其实就是通过学习文本来用词向量的方式表征词的语义信息,即 通过一个嵌入空间使得语义上相似的单词在该空间内距离很近 。Embedding其实就是一个映射,将单词从原先所属的空间映射到新的多维空间中,也就是把原先词所在空间嵌入到一个新的空间中去。 我们从直观角度上来理解一下,cat这个单词和kitten属于语义上很相近的词,而dog和kitten则不是那么相近,iphone这个单词和kitten的语义就差的更远了。通过对词汇表中单词进行这种数值表示方式的学习(也就是将单词转换为词向量),能够让我们基于这样的数值进行向量化的操作从而得到一些有趣的结论。比如说,如果我们对词向量kitten、cat以及dog执行这样的操作:kitten - cat + dog,那么最终得到的嵌入向量(embedded vector)将与puppy这个词向量十分相近。 第一部分 模型...

Tokenizer 背景与基础 目前的机器学习模型都是数学模型,其对应的输入要求必须是数字形式(number)的,而我们处理的真实场景往往会包含许多非数字形式的输入(有时候即使原始输入是数字形式,我们也需要转换),最典型的就是 NLP 中的文字(string),为了让文字能够作为输入参与到模型的计算中去,我们就需要构建一个映射关系(mapping):将对应的文字映射到一个数字形式上去,而其对应的数字就是 token。而对应的这个映射关系,就是我们的 tokenizer:他可以将文字映射到其对应的数字上去(encode),也可以将数字映射回对应的文字上(decode)。 诸如GPT-3/4以及LlaMA/LlaMA2大语言模型都采用了token的作为模型的输入输出,其输入是文本,然后将文本转为token(正整数),然后从一串token(对应于文本)预测下一个token。 进入OpenAI官网提供的tokenizer可以看到GPT-3tokenizer采用的方法。这里以Hello World为例说明。...
NLP
2026-03-16
不同于RNN、CNN等模型,对于Transformer模型来说,位置编码的加入是必不可少的,因为纯粹的Attention模块是无法捕捉输入顺序的,即无法区分不同位置的Token。为此我们大体有两个选择: 想办法将位置信息融入到输入中,这构成了绝对位置编码的一般做法; 想办法微调一下Attention结构,使得它有能力分辨不同位置的Token,这构成了相对位置编码的一般做法。 虽然说起来主要就是绝对位置编码和相对位置编码两大类,但每一类其实又能衍生出各种各样的变种,为此研究人员可算是煞费苦心、绞尽脑汁了,此外还有一些不按套路出牌的位置编码。本文就让我们来欣赏一下研究人员为了更好地表达位置信息所构建出来的“八仙过海,各显神通”般的编码方案。 绝对位置编码 形式上来看,绝对位置编码是相对简单的一种方案,但即便如此,也不妨碍各路研究人员的奇思妙想,也有不少的变种。一般来说,绝对位置编码会加到输入中:在输入的第 𝑘 个向量 \(𝑥_𝑘\) 中加入位置向量 \(𝑝_𝑘\) 变为 \(\boldsymbol{x}_k + \boldsymbol{p}_k\) ,其中 \(...
NLP
2026-01-24

旋转式位置编码(ROPE) 原始的Sinusoidal位置编码总的感觉是一种“想要成为相对位置编码的绝对位置编码”。一般来说,绝对位置编码具有实现简单、计算速度快等优点,而相对位置编码则直接地体现了相对位置信号,跟我们的直观理解吻合,实际性能往往也更好。由此可见,如果可以通过绝对位置编码的方式实现相对位置编码,那么就是“集各家之所长”、“鱼与熊掌兼得”了。Sinusoidal位置编码隐约做到了这一点,但并不够好。 本文将会介绍我们自研的Rotary Transformer(RoFormer)模型,它的主要改动是应用了笔者构思的“旋转式位置编码(Rotary Position Embedding,RoPE)”,这是一种配合Attention机制能达到“绝对位置编码的方式实现相对位置编码”的设计。而也正因为这种设计,它还是目前唯一一种可用于线性Attention的相对位置编码。 RoFormer:https://github.com/ZhuiyiTechnology/roformer 基本思路 这里简要介绍过RoPE: Transformer位置编码...
NLP
2026-01-22
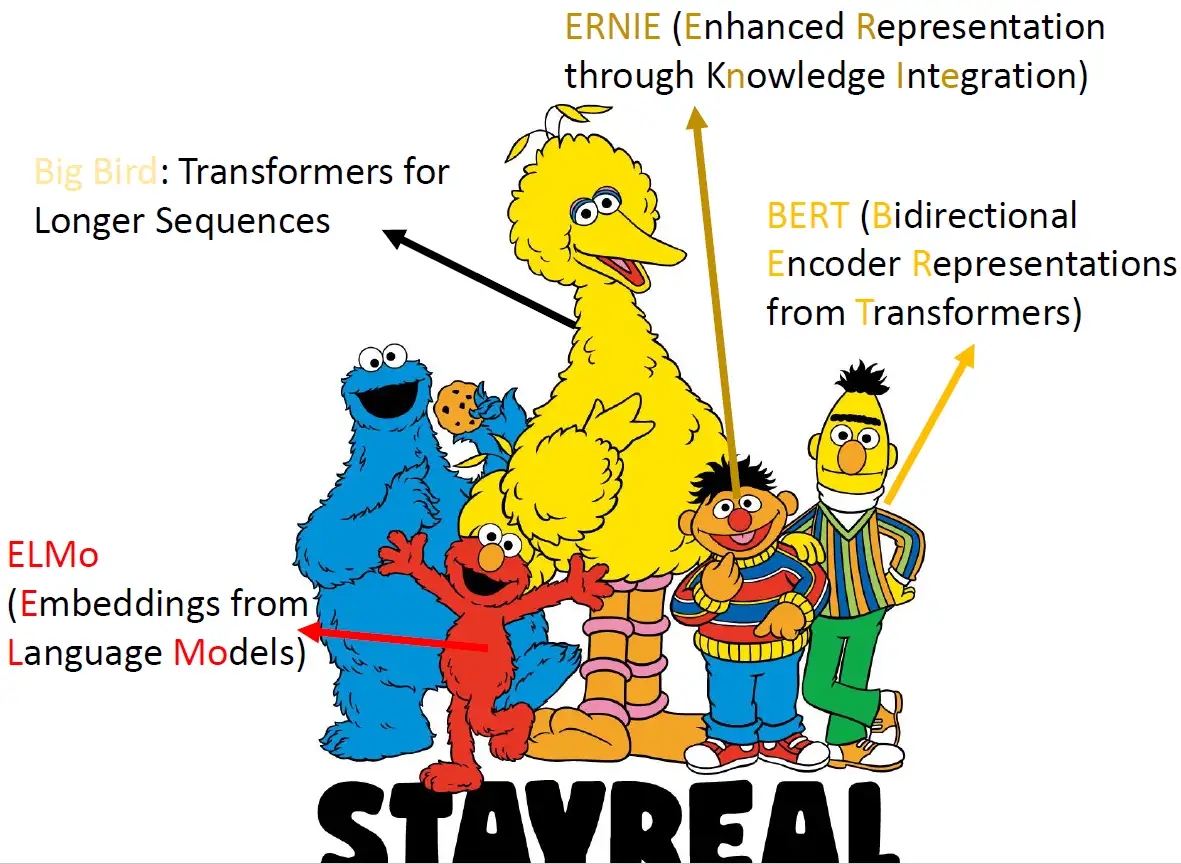
Self-Supervised Learning ,又称为自监督学习,我们知道一般机器学习分为有监督学习,无监督学习和强化学习。 而 Self-Supervised Learning 是无监督学习里面的一种,主要是希望能够学习到一种 通用的特征表达 用于 下游任务 (Downstream Tasks) 。 其主要的方式就是通过自己监督自己。作为代表作的 kaiming 的 MoCo 引发一波热议, Yann Lecun也在 AAAI 上讲 Self-Supervised Learning 是未来的大势所趋。所以在这个系列中,我会系统地解读 Self-Supervised Learning 的经典工作。 本文主要介绍 Self-Supervised Learning 在 NLP领域 的经典工作:BERT模型的原理及其变体。 本文来自台湾大学李宏毅老师PPT: https://speech.ee.ntu.edu.tw/~hylee/ml/ml2021-course-data/bert_v8.pdf 芝麻街 在介绍 Self-Supervised Learning...